


MapReduce 2.0运行原理深入探究


MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,概念上,“映射(Map)”和“归约(Reduce)”是其主要思想,它极大地方便了编程人员在不会分布式并行编程的情况下,也能使自己的程序运行在分布式系统上。
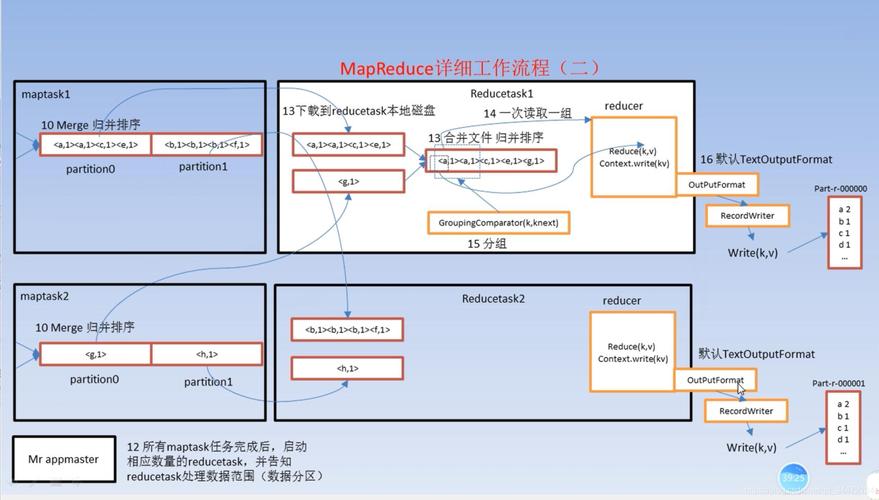
MapReduce 2.0运行原理的核心在于其能够将任务分布至多个计算机节点上进行并行处理,以此达到高效数据处理的目的,其执行过程可以细分为以下几个阶段:输入分片、映射阶段、Shuffle阶段以及归约阶段。
1、输入分片:在MapReduce框架中,输入数据集首先会被分成若干个数据块,每个数据块由一个Mapper负责处理,这种分块的方式允许系统以并行的方式进行数据处理,每个Mapper之间相互独立,互不干扰,从而实现高效的数据处理。
2、映射阶段(Mapping):每个Mapper会对其分配的数据块中的每条数据应用用户定义的映射函数,映射函数的主要作用是将输入数据转换为键值对的形式输出,这些中间键值对随后会被分发到Shuffle阶段以便进行后续操作。
3、Shuffle阶段:Shuffle阶段是连接映射阶段和归约阶段的桥梁,在这一阶段,系统会根据键值对中的键对其进行排序和分组,确保具有相同键的值被发送到同一个Reducer,这一过程中,还可能涉及到数据的压缩和分区操作,以优化数据传输效率和负载均衡。
4、归约阶段(Reducing):在归约阶段,Reducer会接收到来自Shuffle阶段的所有具有相同键的值,然后应用用户定义的归约函数对这些值进行处理,归约函数的操作包括数据合并、数据计数等,最终生成的结果会被写回到文件系统中。
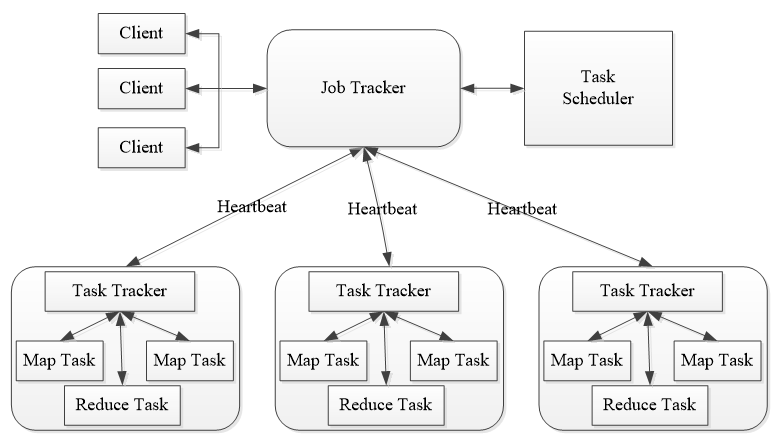
除了上述核心执行流程外,MapReduce 2.0作业的启动、资源文件的准备、作业的提交和任务的跟踪等也是整个运行机制的重要组成部分,客户端在启动一个作业时,需要向JobTracker请求一个作业ID,并将所需的资源文件复制到HDFS上,JobTracker负责作业的调度和跟踪,根据输入划分信息为每个数据划分创建一个map任务,并分配给TaskTracker执行。
MapReduce 2.0通过高度并行的数据处理方式,结合有效的数据分片、映射处理、Shuffle排序及归约操作,实现了对大规模数据集的高效处理,尽管存在一定的局限性,如只支持一个Map阶段和一个Reduce阶段,但对于大数据处理而言,MapReduce 2.0提供了一个相对简单而强大的解决方案。
FAQs
Q1: MapReduce 2.0是否支持多级排序?
A1: MapReduce框架本身不直接支持多级排序,如果需要进行多级排序,可以在Reduce阶段的输出中实施自定义的排序逻辑,或者采用额外的MapReduce作业来进一步处理排序。
Q2: 如何优化MapReduce作业的执行效率?
A2: 优化MapReduce作业的效率可以从以下几个方面考虑:选择合适的数据输入格式以减少数据传输量,合理设置数据分片大小以平衡各个节点的计算量,优化映射和归约函数的复杂度,使用压缩技术减少存储和传输的数据量,以及合理调整MapReduce框架的配置参数,如内存分配和并发任务数等。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/935356.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复