


在机器学习和深度学习领域,loss曲线是一个关键工具,用于显示模型在训练过程中的性能变化,通过分析loss曲线,研究人员可以对模型的训练状态进行诊断,从而采取相应的优化措施以提升模型的泛化能力,一般而言,数据集会被划分为三部分:训练集、验证集和测试集,监控训练过程中这些数据集上的loss变化是至关重要的。
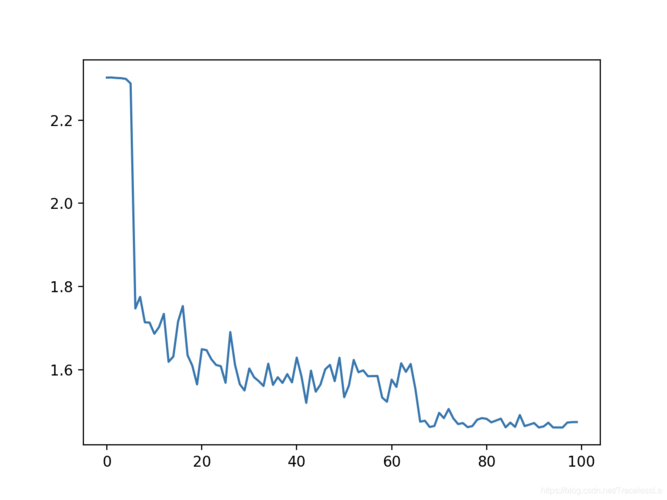

Loss曲线的类型及特点
1、Underfit(欠拟合): 当模型在训练集和验证集上的表现均不佳时,通常呈现为loss下降缓慢或居高不下,出现这种情况可能是因为模型过于简单,无法捕捉数据的复杂性。
2、Overfit(过拟合): 当模型在训练集上表现良好,但在验证集上的表现差强人意时,这通常表明模型过度拟合了训练数据,训练集loss继续下降而验证集loss开始上升,说明模型学习到了训练数据中的噪声而非真正的模式。
3、Good fit(完美拟合): 理想的情况是模型在训练集和验证集上都有良好表现,两者的loss都逐渐下降并在某个点趋于稳定,这表明模型具有良好的泛化能力。
Loss曲线的分析与优化
分析Loss曲线: 观察loss曲线可以帮助我们识别模型当前的状态,如是否出现了过拟合或欠拟合现象,通过比较训练集和验证集的loss曲线,我们可以判断模型是否在两者之间达到了良好的平衡。
优化策略: 对于欠拟合的模型,可以考虑增加模型复杂度或引入更多的特征信息,对于过拟合的情况,常见的解决策略包括增加训练数据量、应用正则化技术或使用dropout等避免过拟合的技巧。
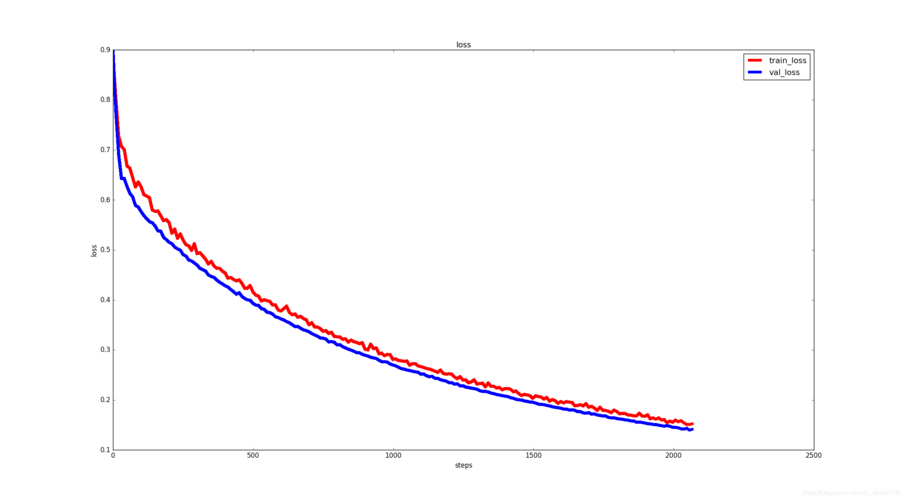
持续监控: 在模型训练过程中应持续监控loss曲线,以便及时发现问题并调整训练策略,有时,适当的调整学习率或更换优化器也可以显著改善loss曲线的表现。
我们使用matplotlib绘制loss曲线,这样的可视化工具能够帮助我们更加直观地理解模型的训练过程:
import matplotlib.pyplot as plt
假设 train_loss 和 val_loss 分别是训练集和验证集的损失值列表
plt.plot(train_loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Loss Curves')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show() 通过上述代码,我们能够生成一个展示训练过程中训练集和验证集loss变化的图表,这对于分析和诊断模型的训练状态非常有帮助。
相关问答FAQs
Q1: 如果验证集的loss比训练集的loss低,这代表了什么?
A1: 通常情况下,验证集的loss不会比训练集的loss低,因为模型是在训练集上进行学习的,如果发生这种情况,可能是由于数据集划分不当或者是测量误差导致的,需要检查数据集的处理和划分过程。
Q2: 如何调整模型以避免过拟合?
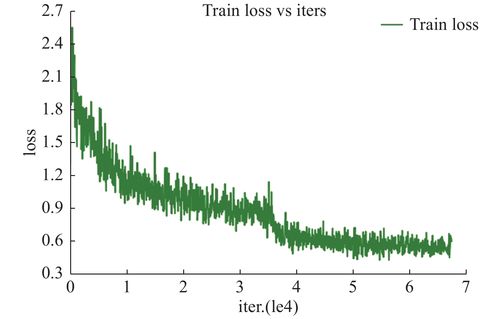
A2: 避免过拟合可以通过多种方式实现,比如增加数据集的规模,使用数据增强技术来扩充数据,应用正则化技术如L1、L2正则化,或者在模型中加入dropout层来随机关闭一部分神经元,减少模型对特定数据的依赖。
loss曲线是理解和优化机器学习模型的关键工具,通过合理分析loss曲线,可以有效指导模型的训练过程,从而实现更好的模型性能和更强的泛化能力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/934492.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复