


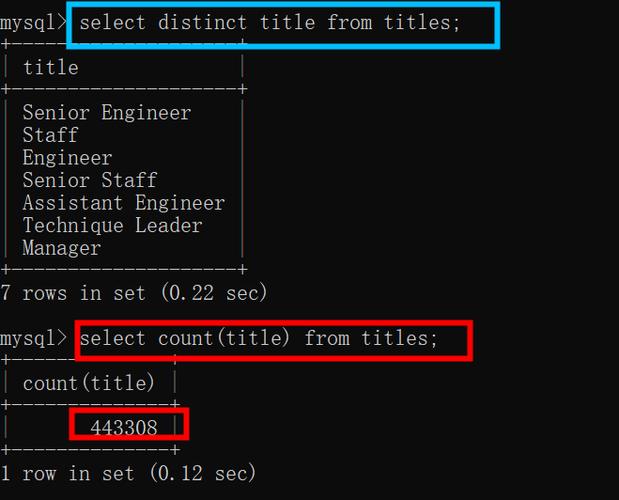
sql,SELECT DISTINCT name FROM students;,“在数据库中,我们经常会遇到重复数据的问题,这些重复的数据可能会对数据分析和处理造成影响,我们需要使用SQL语句来去除这些重复的数据。

去重的基本思路是使用DISTINCT关键字或者GROUP BY子句,DISTINCT关键字可以用于SELECT语句中,用于返回唯一的不同值,而GROUP BY子句则可以将具有相同数据的行分组在一起,然后我们可以使用聚合函数(如COUNT()、SUM()、AVG()等)对这些组进行操作。
我们来看看如何使用DISTINCT关键字进行去重,假设我们有一个名为"students"的表,其中包含学生的姓名和年龄信息,但是有些学生的信息重复了,我们可以使用以下SQL语句来获取所有不重复的学生姓名:
SELECT DISTINCT name FROM students;
这条SQL语句会返回所有不重复的学生姓名,如果你想获取所有不重复的学生姓名和年龄,你可以使用以下SQL语句:
SELECT DISTINCT name, age FROM students;
这条SQL语句会返回所有不重复的学生姓名和年龄的组合。
我们来看看如何使用GROUP BY子句进行去重,假设我们有一个名为"orders"的表,其中包含订单的详细信息,但是有些订单的信息重复了,我们可以使用以下SQL语句来获取每个客户的订单总数:
SELECT customer_id, COUNT(*) as order_count FROM orders GROUP BY customer_id;
这条SQL语句会按照customer_id将订单分组,然后计算每个组的订单数量。
需要注意的是,DISTINCT关键字和GROUP BY子句虽然都可以用于去重,但是它们的使用场景是不同的,DISTINCT关键字主要用于去除查询结果中的重复行,而GROUP BY子句则主要用于对查询结果进行分组,然后对每个组进行聚合操作。
如果你的数据表中有大量的重复数据,你可能需要定期进行去重操作,你可以在你的应用程序中添加一个定时任务,定期执行去重的SQL语句,以保持数据的准确性。
我们来看一下如何使用SQL语句删除数据表中的重复数据,假设我们有一个名为"products"的表,其中包含产品的详细信息,但是有些产品的信息重复了,我们可以使用以下SQL语句来删除重复的产品信息:
DELETE p1 FROM products p1 INNER JOIN products p2 WHERE p1.id > p2.id AND p1.name = p2.name AND p1.price = p2.price;
这条SQL语句会删除那些与另一行在所有列上都有相同值的行,注意,这条SQL语句只适用于那些有主键或者唯一索引的表,因为我们需要一种方法来确定哪些行是"重复的"。
就是关于去重SQL的一些基本知识,希望对你有所帮助。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/932101.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复