


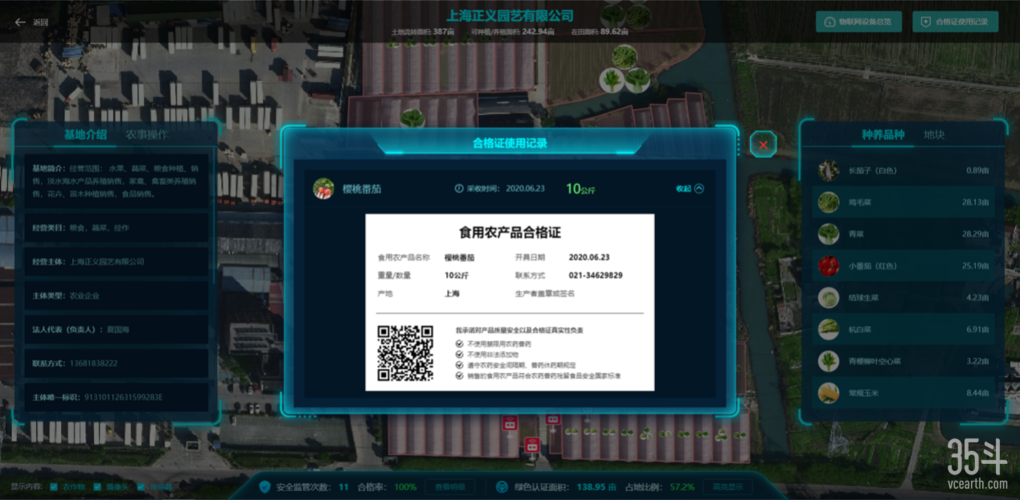

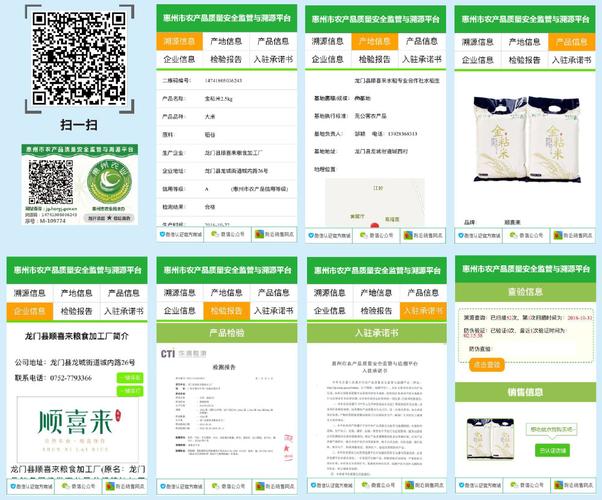
在现代农业中,溯源码的生成和应用越来越受到重视,溯源码能够为消费者提供产品的来源信息、生产流程、质量检测等关键数据,增加农产品的透明度和信任度,小编将介绍一个具有溯源码生成功能的农业网站源码及其数据库的设计。
1. 系统
这个农业网站提供了一个平台,让农业生产者上传产品信息,并自动生成溯源码,消费者可以通过扫描溯源码获取产品的详细信息,包括产地、种植方法、收获日期、质量检验结果等。
2. 功能模块
用户管理:注册、登录、信息修改。
产品管理:添加、编辑、删除产品信息。
溯源码生成:为每个产品生成唯一的溯源码。
信息查询:通过溯源码查询产品详细信息。
3. 数据库设计
数据库设计是整个系统的核心,需要存储用户信息、产品信息、以及溯源码与产品之间的关系,以下是一个简化的数据库表结构设计:
| 表名 | 描述 | 主要字段 |
| users | 用户信息表 | user_id, username, password, contact_info |
| products | 产品信息表 | product_id, user_id, name, category, description, harvest_date, inspection_result |
| trace_codes | 溯源码信息表 | code_id, product_id, trace_code |
users 表存储用户的基本信息,如用户名、密码和联系方式。
products 表存储产品信息,包括产品ID、所属用户ID、名称、类别、描述、收获日期和检验结果等。
trace_codes 表存储每个产品对应的溯源码。
4. 溯源码生成算法
溯源码通常由一串字符组成,可以是数字、字母或二者的组合,生成算法可以基于产品的唯一标识(如product_id),结合时间戳、随机数等元素,以确保每个溯源码的唯一性,可以使用以下伪代码来生成溯源码:
import hashlib
import time
def generate_trace_code(product_id):
timestamp = str(time.time()).replace('.', '')
random_part = ''.join(random.choices('0123456789ABCDEF', k=4))
raw_data = f"{product_id}{timestamp}{random_part}"
trace_code = hashlib.sha256(raw_data.encode()).hexdigest()
return trace_code 5. 实现技术栈
前端:HTML, CSS, JavaScript, Bootstrap(用于快速开发响应式界面)
后端:Python (Django框架) 或 PHP, Node.js等
数据库:MySQL, PostgreSQL, MongoDB等
服务器:Nginx 或 Apache
相关问题与解答
Q1: 如何确保溯源码的安全性?
A1: 溯源码的安全性可以通过多种方式确保,使用哈希算法(如SHA256)可以为每个产品生成几乎唯一的编码,系统应实施适当的安全措施,如SSL/TLS加密,以防止数据在传输过程中被截获,对敏感信息进行加密存储,并限制数据库的访问权限。
Q2: 如果产品信息更新了,溯源码需要重新生成吗?
A2: 这取决于业务需求和溯源码的设计,如果溯源码包含了产品的关键信息(如收获日期),那么这些信息更新后,理论上应该重新生成溯源码,但如果溯源码仅仅是一个指向产品信息的链接或标识符,则不需要重新生成,只要确保通过溯源码能访问到最新的产品信息即可。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/931807.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复