


在深度学习框架Caffe中,Solver扮演着至关重要的角色,其主要功能是实现网络参数的优化,通过交替执行前向(forward)和后向(backward)算法,Solver可以有效地更新参数以最小化loss,这对于训练深度神经网络来说至关重要,本文将深入探讨Caffe中的Solver的作用,优化算法类型,及相关配置细节,使读者能够全面理解其重要性和应用方式。


功能详解
Solver在Caffe框架中的基本职能是调用前向和后向算法来不断更新网络中的参数,这一过程目标是减少定义的loss函数值,以便模型能更好地拟合训练数据,通过这种方式,Solver实际上是实施迭代优化算法,逐步精细化每一层的权重和偏置,直至达到预设的训练目标或迭代次数。
优化算法种类
Caffe提供了多种优化算法供用户选择,以适应不同的模型和数据集要求,到目前为止,主要包括以下六种类型:
1、Stochastic Gradient Descent (SGD): 最常见的优化方法,随机选取样本进行梯度下降。
2、AdaDelta: ENW IMAGE
解决了传统SGD中学习率选择的难题,通过自动调整学习率来加速收敛。
3、Adaptive Gradient (AdaGrad): 对每个参数进行自适应学习率调整,适合处理稀疏数据。
4、Adam: 结合了AdaGrad和动量方法的优势,对不同参数实现自适应学习率调整。
5、Nesterov’s Accelerated Gradient: 增加了一个校正项的动量方法,能更快地收敛。
6、RMSprop: 基于AdaGrad的改进版本,改变了学习率的计算方式,解决其在非凸优化问题上的不足。
Solver配置详解
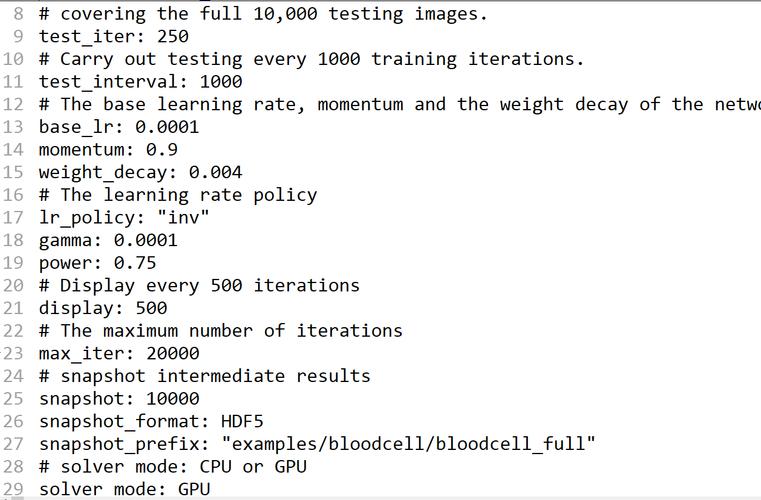
为了有效地使用这些优化算法,Caffe允许用户通过编写Solver配置文件(如lenet_train_test.prototxt)来详细设置各种参数,可以设定学习率、测试迭代次数(test_iter)、基础学习率(base_lr),以及学习策略等,这种灵活性确保了用户可以针对特定任务微调模型,以达到最优训练效果。
应用及影响

选择合适的优化算法对于模型的性能有着直接的影响,SGD虽然简单易用,但在复杂的模型或大规模数据集上可能不够高效;而像Adam这样的自适应学习率方法则可以在这些情况下提供更快的收敛速度和更好的结果,适当的配置如学习率调整策略和正则化方法也能显著影响模型的泛化能力和训练效率。
归纳而言,Caffe中的Solver是一个强大的工具,它通过实现各种优化算法帮助训练高效的深度学习模型,了解每种算法的特点及其适用场景,以及如何正确地配置Solver,对于深度学习项目的成功至关重要,通过精心选择和调整这些参数,用户可以充分利用Caffe的强大功能,推动各类机器学习任务向前发展。
FAQs
Q1: Caffe中的Solver支持哪些优化算法?
A1: Caffe中的Solver支持六种优化算法:Stochastic Gradient Descent (SGD), AdaDelta, Adaptive Gradient (AdaGrad), Adam, Nesterov’s Accelerated Gradient, 和 RMSprop。
Q2: Solver在训练过程中的主要作用是什么?
A2: Solver的主要作用是通过交替调用前向和后向算法来更新网络参数,从而最小化loss函数,优化模型性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/929881.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复