


DISTINCT关键字实现。如果你想从students表中选取不重复的name值,可以使用以下SQL语句:,,“sql,SELECT DISTINCT name FROM students;,`,,这将返回一个结果集,其中每个name值只出现一次,即使它在students`表中多次出现。在数据库的日常管理和操作过程中,去重是一项重要的数据清洗工作,特别是在使用如MySQL这样的关系型数据库管理系统时,有效地去除重复的数据行不仅可以节省存储空间,还能提高查询效率和数据质量,本文将详细介绍在MySQL中实现数据去重的多种方法及其适用场景,帮助初学者和开发者更加精确地掌握相关技巧。
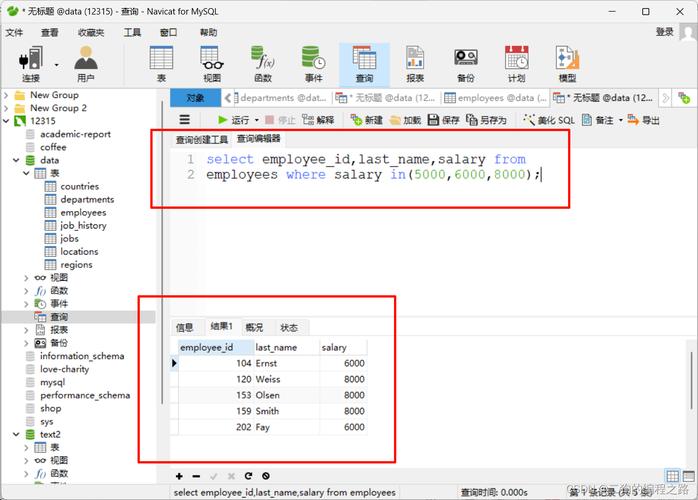

全部字段去重
在需要从表中删除所有字段都相同的重复行时,可以使用DELETE联合JOIN的语句,假设有一个名为students的表,并且需要删除所有字段完全相同的记录,可以执行如下SQL命令:
DELETE s1 FROM students s1 INNER JOIN students s2 WHERE s1.id > s2.id AND s1.name = s2.name;
这个命令通过自连接students表,并比较行之间的id和其他字段,保留具有最小id的记录,从而去除重复项。
基于部分字段去重
当需要根据特定的某些字段进行去重时,可以使用ROW_NUMBER()窗口函数,如果要根据name和age字段去除students表中的重复记录,可以使用以下查询:
DELETE FROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY name, age ORDER BY id) AS rownum FROM students ) t WHERE t.rownum > 1;
这里,ROW_NUMBER()函数为每个分窗(由PARTITION BY定义)中的行分配一个唯一的数字,根据id排序,从而实现只保留每个分区的第一行(即保留每个姓名和年龄组合下的最小id记录)。
使用 DISTINCT 关键字

DISTINCT关键字用于返回唯一不同的值,在查询中,如果你只想看到某个字段的唯一值,可以使用DISTINCt,如:
SELECT DISTINCT city FROM customers;
这将返回customers表中city字段的所有不同值。
使用 GROUP BY 分组
虽然DISTINCT可以快速返回唯一值,但当需要对每个不同值进行聚合运算时(如计数),则应使用GROUP BY。
SELECT city, COUNT(*) as order_count FROM customers GROUP BY city;
此查询不仅列出了不同的city值,还计算了每个城市的客户数量。
方法各适用于不同的数据去重需求场景,选择合适的去重策略,可以有效地提升数据库的查询性能和数据可用性。
相关问答 FAQs
Q1: 使用DISTINCT和GROUP BY有什么不同?
A1:DISTINCT主要用于返回选定列的唯一值,而不进行任何其他计算,适用于简单的去重显示需求,而GROUP BY不仅去重,还能进行聚合计算如求和、计数等,适合复杂的数据分析需求。
Q2: 在大数据表中去重会影响性能吗?
A2: 是的,特别是在大数据集上进行去重操作时,可能会对性能产生影响,因为去重操作通常需要扫描整个表以识别和删除重复的行,适当的索引和优化查询可以改善性能,在某些情况下,可以考虑使用批处理或定期清理任务来减少一次性操作的影响。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/926681.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复