


内容过滤接口是一种用于自动识别和过滤掉不适宜、有害或违规内容的系统,这种接口通常被集成到在线平台、社交媒体、论坛和其他需要维护健康交流环境的场所,数据过滤可以基于文本、图片、音频和视频等不同类型的数据进行。

工作原理
过滤接口的工作原理通常涉及以下几个步骤:
1、输入数据 用户上传的内容(如文本、图片、视频)作为输入进入过滤系统。
2、预处理 对输入数据进行格式化处理,例如将文本标准化、图像压缩等。
3、特征提取 从预处理后的数据中提取关键特征,这些特征可以是关键词、图像的颜色直方图、声音的频率模式等。
4、模型分析 使用机器学习模型(如自然语言处理模型、深度学习网络)来分析提取的特征,并判断内容是否违反了预设的规则。
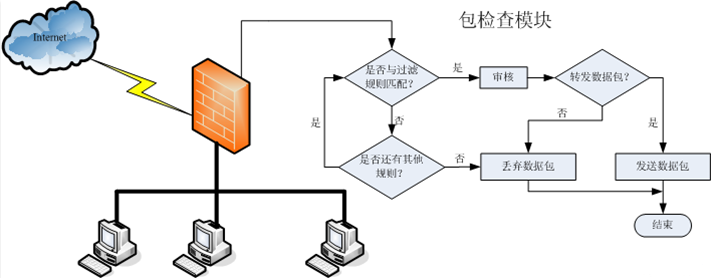
5、决策与执行 根据模型的分析结果,系统决定是否允许内容发布或是将其标记、删除或以其他方式处理。
关键技术
自然语言处理(NLP) 对于文本数据,NLP技术可以帮助理解和解释人类语言,从而识别出不当言论或敏感信息。
计算机视觉 对于图像和视频数据,计算机视觉技术可以识别不适当或违规的视觉内容。
语音识别 对于音频数据,通过语音识别技术可以将语音转换成文本,进而应用NLP进行分析。

机器学习与深度学习 利用算法训练模型以识别和预测不良内容,不断优化过滤效果。
应用场景
社交媒体平台 自动检测和移除辱骂性言论、仇恨言论、色情内容等。
论坛和评论区 防止垃圾信息、广告和非法内容的泛滥。
电子邮件服务 过滤垃圾邮件和网络钓鱼尝试。
直播平台 实时监控直播内容,确保符合规定标准。
挑战与限制
误判率 过滤系统可能会错误地屏蔽合法内容(假阳性)或漏过违规内容(假阴性)。
文化敏感性 不同文化和社会对“不适宜”内容的定义可能不同,过滤系统需适应多样化的标准。
技术局限性 当前技术仍无法完美解决复杂语境下的语义理解问题。
隐私权问题 内容过滤可能涉及到用户隐私数据的处理,需要严格遵守数据保护法规。
相关问题与解答
Q1: 如何提高内容过滤接口的准确性?
A1: 提高准确性可以通过以下几种方式实现:
持续更新和优化过滤器中使用的数据集,确保其反映最新的违规内容形式。
采用更先进的机器学习模型,如深度学习,以提高对复杂模式的识别能力。
结合多种检测技术,例如同时使用NLP和计算机视觉技术来增强过滤效果。
增加用户反馈机制,利用人工审核来校正模型的错误判断,并以此改进算法。
Q2: 内容过滤接口在处理多语言内容时面临哪些挑战?
A2: 处理多语言内容时的挑战包括:
语言差异性 不同语言有其独特的语法结构和表达方式,要求过滤系统能够适应各种语言特性。
资源可用性 某些小众语言可能缺乏足够的训练数据和预处理工具,导致过滤效果不佳。
文化敏感性 同一词汇在不同文化背景下可能具有不同含义,需要过滤系统能够理解并正确处理这些差异。
翻译准确性 在需要将内容翻译成统一语言进行处理的情况下,翻译的准确性直接影响过滤结果。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/926633.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复