


Tokenize在自然语言处理中的重要性

Tokenize是自然语言处理(NLP)领域的一个基础而关键的过程,它负责将原始文本数据转换成机器可理解和处理的格式,这一过程为文本预处理阶段的重要组成部分,为后续的任务如自然语言理解、文本分类、情感分析等提供了必要的数据基础,通过Tokenize处理,原始文本被分解成更易于分析和理解的小单元,这些小单元被称为tokens。
Tokenization的基本概念和目的
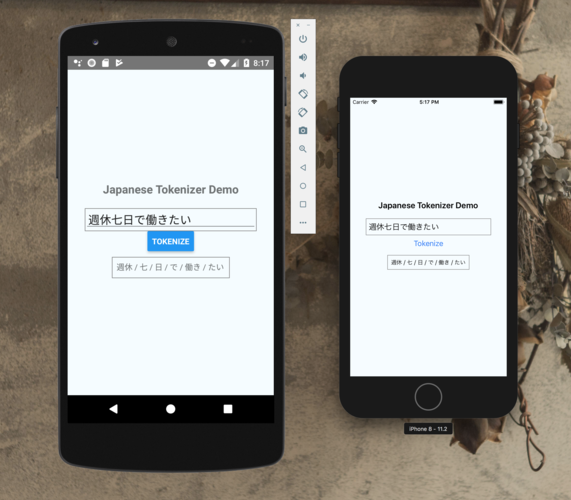
Tokenization或分词是将文本拆分成小块(称为tokens)的过程,每个token通常是一个词或短语,但也可以是字符或其他语义单位,此过程的主要目的是简化文本数据,使之能够被算法有效处理,句子“自然语言处理是AI的一个分支”可以被分词为“自然语言/处理/是/AI/的/一个/分支”。
Tokenizer的类型与选择
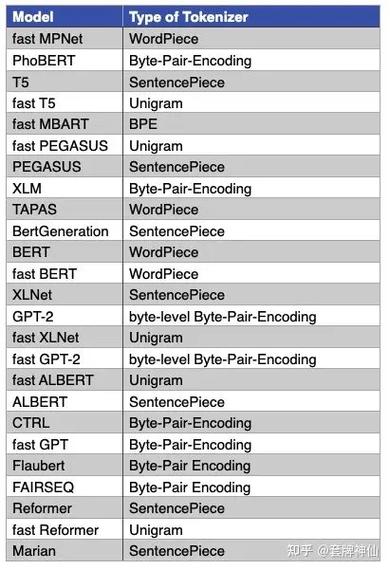
Tokenizer的选择取决于特定的应用需求和文本数据的特性,如SentencePiece是目前流行的一种Tokenizer,由Google开发,其流行的原因包括语言无关性、数据驱动等特点,适用于大规模的机器学习模型。
Tokenization在NLP中的应用
1、文本分类:在文本分类任务中,Tokenize作为第一步,帮助将文档分解成可以量化的特征向量,这对于后续的分类模型训练至关重要,因为它决定了分类器能够学习和区分的特征质量。
2、情感分析:情感分析或意见挖掘中,Tokenize帮助识别和分离文本中的观点和情感表达,使模型能更准确地评估情绪倾向。
3、机器翻译:在机器翻译应用中,源语言文本必须先经过Tokenize处理,才能进行有效的编码和向目标语言的转换。
Tokenization的技术细节
1、输入解析标记:Tokenizer需要一个输入参数,这通常是一个生成器函数,如tokenize.tokenize(readline),这里的readline必须是能够产生文本行的可调用对象。
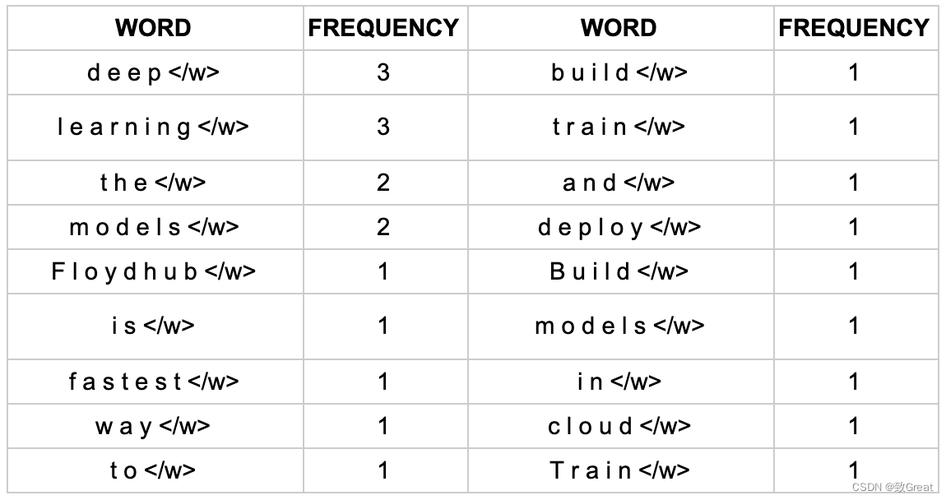
2、文本到整数序列的转换:为了在机器学习模型中使用,Tokenizer不仅将文本分解成tokens,还会将这些tokens转换为整数序列,这使得处理大量文本数据变得更加高效,因为数字计算比文本处理更快。
Tokenizer工具和方法
1、Tokenize, Encode和Encode Plus:这些是Tokenizer库中常见的方法。Tokenize负责实际的文本分词,Encode将分词后的文本转换为数字编码,而Encode Plus则提供更丰富的信息,如单词的开始和结束位置等,以支持更复杂的NLP任务。
相关工具与实现方式
1、Python中的实现:Python提供了多种库来支持Tokenization,如NLTK、spaCy等,这些库不仅提供Tokenize功能,还包括许多其他NLP工具,如词性标注和命名实体识别等。
2、自定义Tokenization:对于特定领域或语言,可能需要开发自定义的Tokenizer,这可以通过编程实现特定的分词逻辑或使用现有的NLP库进行扩展来实现。
实际案例与操作示例
1、新闻文章的主题分类:在进行新闻文章的主题分类时,首先需要对文章标题和内容进行Tokenize处理,这些tokens会被转换成数值输入到一个分类模型中,该模型根据学习到的tokens与主题之间的关系进行预测。
2、社交媒体数据分析:在分析社交媒体数据时,Tokenize帮助从用户帖子中提取关键词和话题标签,进而分析公众对某一事件或产品的情绪反应。
在接下来的部分,我们将探讨一些常见问题及其解答,以便更好地理解Tokenize在实际应用中的一些关键考虑因素。
FAQs
什么是Tokenize的最佳实践?
Tokenize的最佳实践包括选择合适的Tokenizer(考虑语言特性和任务需求),确保文本数据清洗(去除噪声数据如无意义的标点符号和特殊字符),以及适当地处理未知词汇,这些步骤确保了文本数据可以有效地转换成高质量的tokens,从而提高NLP任务的性能。
如何优化Tokenizer的性能?
优化Tokenizer性能的方法包括使用高效的算法和数据结构来减少处理时间,利用并行处理技术加快大规模文本的处理速度,以及定期更新Tokenizer的词汇库以适应语言的演变和新出现的术语,针对特定任务调整Tokenizer的参数(如token的长度、停用词的过滤等)也是提高性能的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/925794.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复