


float类型数据存储方式

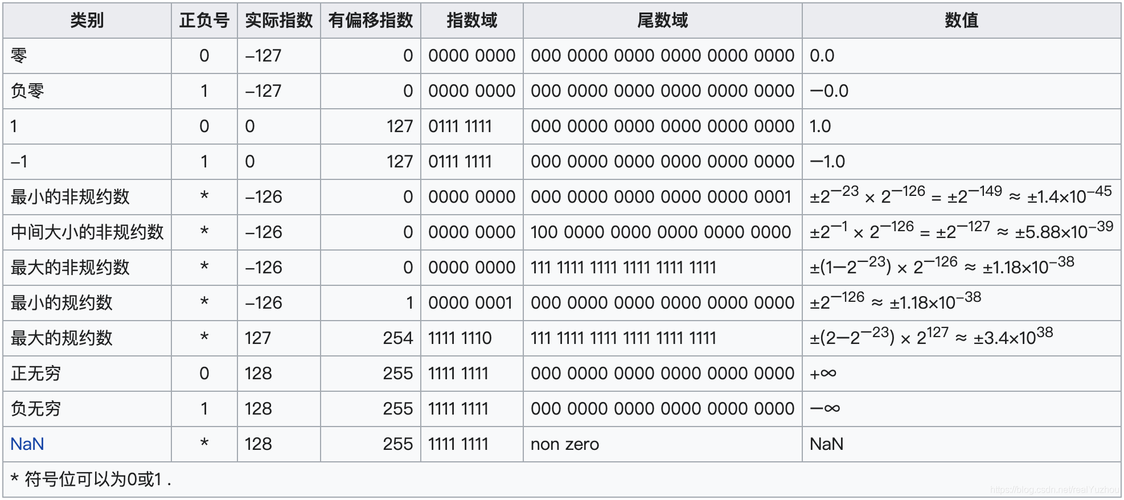
在计算机科学中,float类型数据是按照IEEE 754标准进行存储的,该标准规定了浮点数的存储格式,它包括三个主要部分:符号位、指数部分和尾数部分,具体而言,32位浮点数(即float类型)分配1位给符号位(决定数值的正负),8位给指数部分,而剩下的23位用于存储尾数,也就是有效数字。
float类型精度限制
由于float类型只有有限的32位来表示一个数值,这意味着它无法无限精确地表示所有实数,特别是,当数值很大或很小的时候,float类型的精度会受限于它的存储位数,这种精度损失通常表现为数值舍入误差,尤其是在进行数学运算时更为明显。
float取值范围
根据IEEE 754标准,32位浮点数(float类型)可以表示的取值范围大约在(3.4E38)到(3.4E+38)之间,这个范围是通过公式计算出来的,其中指数部分经过偏置处理后得到的实际指数范围决定了float类型可以表示的最小和最大数。
特殊值表示方法
除了普通的数值,float类型还可以表示一些特殊值,如零、正无穷大、负无穷大以及NaN(非数字),这些特殊值通过特定的指数和尾数的组合来表示,指数部分全为1,尾数部分全为0时,表示为NaN;当指数部分全为1,尾数部分全为0,且符号位为0时,表示为正无穷大,符号位为1时则表示为负无穷大。

避免精度损失
尽管float类型存在精度限制,但通过一些方法可以减少精度损失,可以使用更高精度的数据类型(如double),或者在涉及大量数学运算时小心地安排计算顺序,对于金融等需要高精度计算的领域,应避免使用浮点数来存储货币值。
指数计算
在IEEE 754标准中,float的指数部分是有偏的,这意味着实际存储的指数值与表示的数值大小之间的关系并不是直接的,指数部分存储的值是实际指数加上一个偏置值(bias),对于float类型,这个偏置值是127,这样的设计允许浮点数表示非常大的数值和非常小的数值,同时还能区分正数、负数和各种特殊值。
尾数理解
尾数部分代表了浮点数的有效数字,对于float类型而言,尾数有23位,在规格化数中,尾数部分是一个形如1.xx…的二进制数,1”是隐含的并不用存储,只需要存储小数部分(即xx…部分),尾数的这种设计使得float能够以有限的位数存储尽可能多的有效数字,从而提高了表示精度。
相关FAQs
float和double的区别是什么?
float和double都是浮点数类型,但它们的主要区别在于精度和取值范围,float是单精度浮点数,通常占用4个字节(32位),其取值范围大约在(3.4E38)到(3.4E+38)之间,而double是双精度浮点数,占用8个字节(64位),具有更宽泛的取值范围和更高的精度,double的取值范围大约在(1.79E308)到(1.79E+308)之间。
为什么浮点数会有精度问题?
浮点数的精度问题主要是由于它们的存储格式限制造成的,因为浮点数使用固定数量的位来存储,所以它们不能无限精确地表示所有实数,当进行数学运算时,尤其是涉及多个操作数和结果需要舍入的情况下,精度损失可能会累积,导致最终结果与理想值之间存在误差,这个问题在float类型中更加常见,因为它的位数比double少。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/925355.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复