


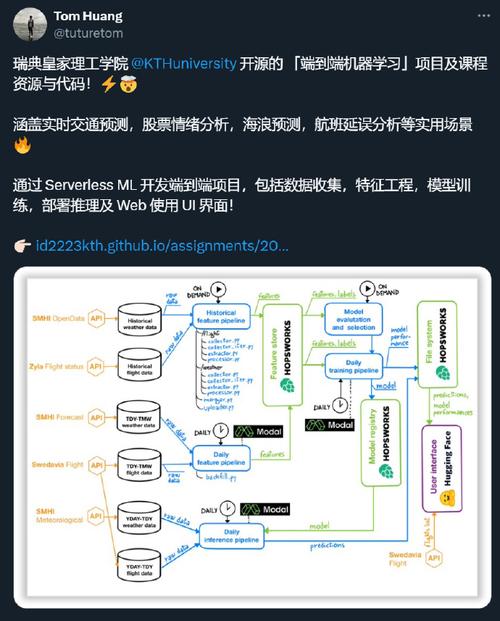

在机器学习中,纳什均衡通常与博弈论相关,纳什均衡是博弈论中的一个关键概念,指的是一种状态,在这种状态下,任何一个参与者单方面改变其策略都不会得到更好的结果,在多智能体学习(MultiAgent Learning)场景中,纳什均衡可以被视为一个目标,即找到一种策略配置,使得每个智能体都无法通过改变自己的策略来获得更高的收益。
1. 基础理论
在多智能体系统中,智能体之间的交互可以被建模为一个博弈,每个智能体的目标是最大化自己的收益,这取决于所有智能体的策略组合,纳什均衡是这样一个策略组合,其中每个智能体选择的策略都是在假设其他智能体策略不变的情况下的最优响应。
2. 算法实现
为了简化,我们考虑一个简单的双矩阵博弈场景,使用Python进行代码实现。
import numpy as np
定义支付矩阵
R = np.array([[3, 1], [0, 2]]) # 玩家1的收益
S = np.array([[2, 2], [1, 1]]) # 玩家2的收益
def best_response(A, B):
"""返回针对给定对手策略的最佳响应"""
A_br = np.argmax(A.T, axis=1)
B_br = np.argmax(B, axis=0)
return A_br, B_br
def nash_equilibrium(R, S):
"""寻找纳什均衡点"""
nash_eq = False
while not nash_eq:
A, B = best_response(R, S)
nash_eq = (A == B).all()
if not nash_eq:
R, S = S, R
return A
寻找纳什均衡
ne = nash_equilibrium(R, S)
print("纳什均衡策略:", ne) 这段代码首先定义了两个玩家的收益矩阵R和S,然后通过迭代的方式寻找纳什均衡点,每次迭代中,它计算当前策略下的最佳响应,并检查是否达到均衡(即两个玩家的最佳响应相同),如果没有达到均衡,则交换收益矩阵继续迭代。
3. 应用场景
纳什均衡的概念不仅用于经济学中的博弈分析,还可以应用于机器学习中的多智能体系统,如自动驾驶车辆的决策制定、机器人足球比赛策略等,在这些应用中,智能体需要根据其他智能体的行为来决定自己的行动策略,以达成一种平衡状态。
相关问题与解答
Q1: 如何判断一个游戏是否存在纯策略纳什均衡?
A1: 对于有限博弈,即参与者数量和每个参与者的策略数量都是有限的情况,根据纳什定理,任何这样的游戏都存在至少一个混合策略纳什均衡,对于纯策略均衡的存在性,可以通过计算每个参与者针对其他参与者策略的最佳响应来检查,如果所有参与者的最佳响应构成一个稳定集合,则存在纯策略纳什均衡。
Q2: 纳什均衡是否总是导致最优的社会结果?
A2: 并不一定,纳什均衡描述的是个体理性的结果,即在均衡状态下,没有任何参与者能够通过单方面改变策略来提高自己的收益,这并不保证社会整体福利最大化,在某些情况下,纳什均衡可能导致效率低下的结果,这种现象被称为“囚徒困境”,设计机制时需要考虑如何激励参与者采取能够提高社会福利的行为。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/923544.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复