

在机器学习领域,端到端的学习模式是一种将整个学习流程整合为一体的方法,这种模式特别适用于机器视觉任务,因为它允许模型直接从原始数据中学习特征,而无需分步骤手工设计特征,小编将探讨端到端学习在机器视觉中的应用,并分享一些实际的学习经验。
端到端学习基础
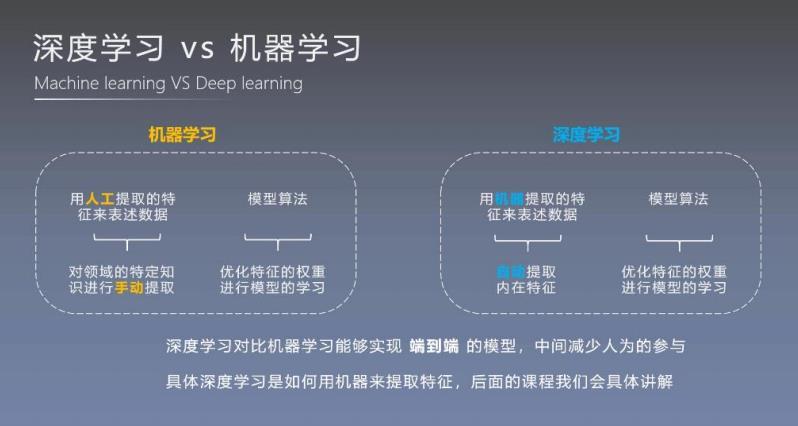
1、定义与原理
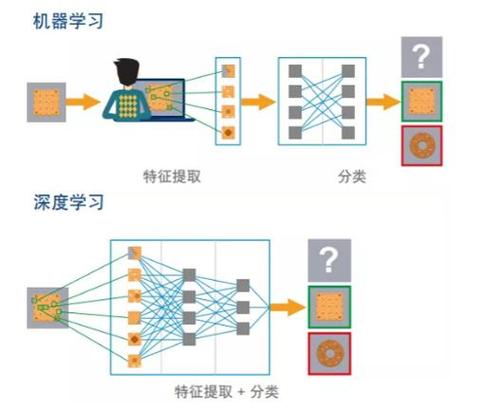
概念理解:端到端学习指的是输入为原始数据(如图像),输出为最终结果(如分类标签)的过程,中间的特征提取和分类过程完全由模型自动完成。
核心优势:该方法的核心优势在于简化了模型开发流程,减少了人工干预,提高了模型的自适应能力和泛化能力。
2、技术实现
深度学习框架:深度卷积神经网络(CNN)是实现端到端学习的典型例子,通过多层结构自动学习图像的特征和表示。
训练过程:端到端的训练需要大量的数据和强大的计算资源,通常在GPU上进行以加速计算过程。
3、应用场景
图像识别:在图像识别领域,端到端模型可以处理图像分类、对象检测等任务。
视频分析:视频分析中,端到端模型能够实现动作识别、场景标记等高级功能。
学习经验分享
1、环境配置
硬件选择:选择合适的硬件,尤其是具备高性能GPU的计算机,这对于加速深度学习模型的训练至关重要。
软件框架:熟悉并安装深度学习库和框架,如TensorFlow或PyTorch,这些工具提供了构建和训练端到端模型所需的各种功能。
2、数据准备
数据采集:根据所需处理的问题收集足够的图像或视频数据,使用多种来源的数据可以增加模型的泛化能力。
预处理操作:虽然端到端模型尽量减少预处理步骤,基本的归一化、去噪等数据预处理操作仍然是必要的。
3、模型设计与训练
模型架构:设计适合特定任务的神经网络架构,例如选择适当的层数和激活函数。
训练策略:采用合适的损失函数和优化器,设置合理的学习率和批量大小,这些都会影响训练的效率和模型的性能。
4、性能评估与调优
评估指标:使用准确率、召回率以及F1分数等指标来评价模型性能。
模型调优:根据评估结果调整模型参数或架构,实验不同的正则化技术以防止过拟合。
实际问题解答
1、硬件资源有限的情况如何训练端到端模型?
可以考虑使用云平台提供的GPU资源,或者选择轻量级的网络结构,同时也可以采用模型压缩和剪枝技术减少资源需求。
2、如何处理数据不足的问题?
可以通过数据增强技术(如旋转、缩放、翻转等)来扩充数据集,另外也可以使用迁移学习,利用预训练的模型来改善小数据集的性能表现。
端到端的机器视觉学习提供了一个从原始输入到最终输出的一体化解决方案,极大地简化了特征工程和模型设计的复杂度,通过上述的学习经验和技巧,用户可以更有效地实现和应用这种强大的学习范式。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/922670.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。