


在MySQL数据库中,回表是一种常见的操作,它与索引的结构和使用密切相关,本文将深入探讨MySQL回表的概念、触发条件、性能考量以及如何通过优化索引减少回表操作,从而提高数据库查询效率,还将通过实例分析,了解如何识别和优化回表操作,以及如何利用覆盖索引来避免不必要的回表,以提升整体的数据库性能。

定义及触发条件
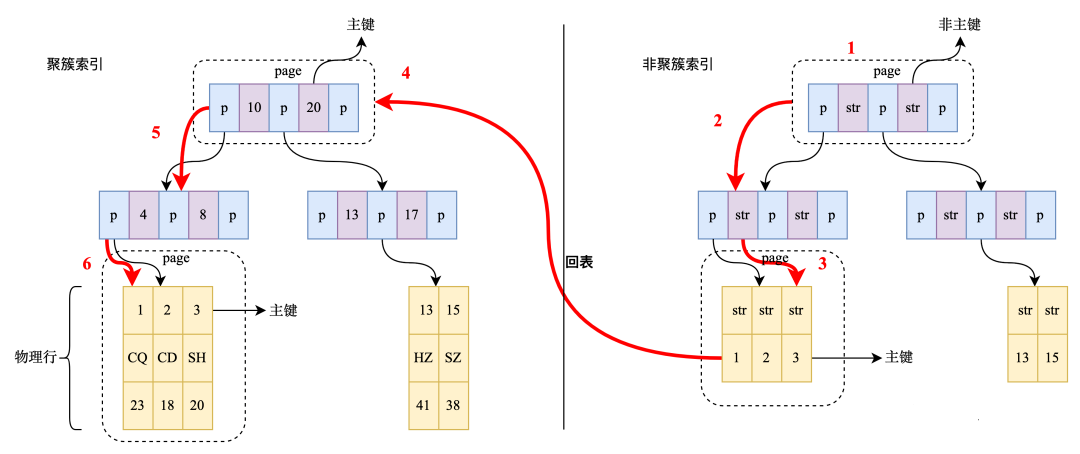
回表,顾名思义,是在通过非主键索引查找数据时需要返回主键索引再次查找的过程,当查询使用的索引没有包含所有需要的数据字段时,数据库首先通过该索引定位到数据的主键值,然后使用这个主键值去主键索引中找到完整的行数据,这一过程就是回表。
不触发条件
相反地,如果查询所需的数据全部包含在所使用的索引中,则不需要进行回表操作,这种情况被称为“索引覆盖”,索引覆盖能够有效提高查询效率,因为它避免了对主键索引的二次查询。
性能考量
回表操作虽然能够帮助我们获取完整的数据记录,但它也带来了额外的性能开销,每次回表都意味着额外的主键索引搜索,这增加了查询的I/O成本,特别是在数据量巨大的情况下,频繁的回表操作可能会导致性能瓶颈。
如何避免不必要的回表
1、优化索引设计:设计索引时,应尽量考虑使用联合索引,将查询中经常一起使用的列包含在内,以实现索引覆盖,减少回表的需要。
2、充分利用覆盖索引:如前所述,覆盖索引可以避免回表,在设计表结构时,应充分考虑查询需求,合理构建索引,使其包含所有查询所需的字段。
3、分析查询语句:通过EXPLAIN命令分析查询语句的执行计划,识别哪些查询导致了回表,并针对性地进行优化。
底层原理
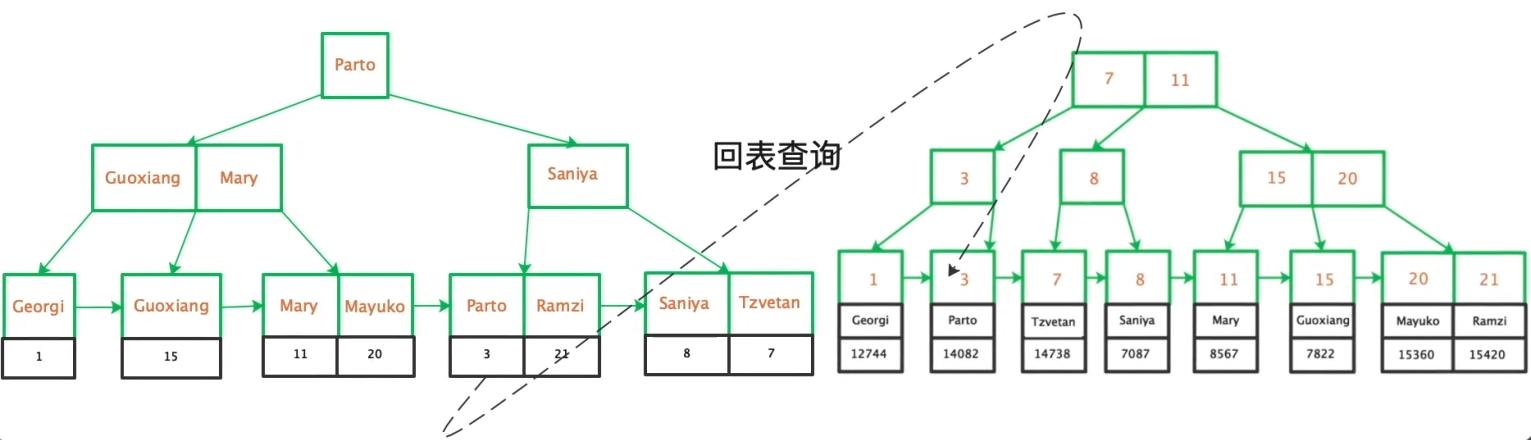
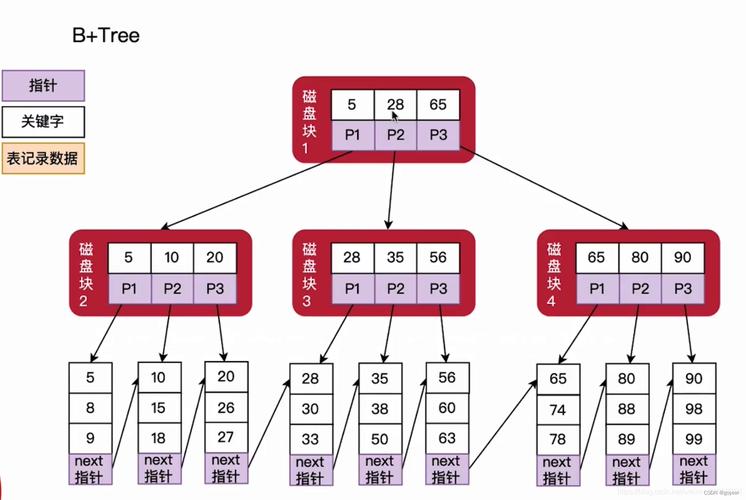
理解MySQL的索引结构和存储引擎是深入掌握回表操作的关键,MySQL默认使用InnoDB存储引擎,其数据被存储在B+树结构中,在InnoDB中,每个表都有一个主键索引(Clustered Index),实际的表数据就存储在这个主键索引的叶子节点中,而次级索引(Secondary Indexes)则包含对应主键的值,通过次级索引查找数据时,如果发现所需数据不在索引中,就会通过主键值回表查询完整的数据记录。
案例分析
假设有一个用户表,包含字段id, name, email等,其中id为主键,现在创建一个联合索引(name, email),当执行查询SELECT id, name, email FROM users WHERE name='John'时,如果name, email两列的值能完全满足查询需求,就无需回表;但如果查询是SELECT id, name, email, address FROM users WHERE name='John',则由于address字段不在索引中,需要进行回表操作。
优化策略
对于上述案例中的第二种情况,一个可能的优化策略是添加address字段到索引中,形成(name, email, address)的联合索引,从而实现索引覆盖,减少回表次数,需要注意的是,增加索引会消耗更多的磁盘空间,并可能影响写入性能,因此需要根据实际情况权衡利弊。
相关问答FAQs
Q1: 什么是覆盖索引?
A1: 覆盖索引是指一个索引包含了所有查询所需的字段,从而使得数据库引擎仅通过访问索引就能完成整个查询,无需再回表读取完整记录,覆盖索引可以显著提高查询效率,减少I/O操作。
Q2: 如何确定查询是否触发了回表?
A2: 可以使用MySQL的EXPLAIN命令来查看查询的执行计划,如果输出结果中的type为“ref”或“range”,并且使用了非主键索引,同时Extra列显示“Using where; Using index”,则表示发生了回表,若Extra显示“Using index”则表示实现了索引覆盖,避免了回表。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/917662.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复