


文章正文


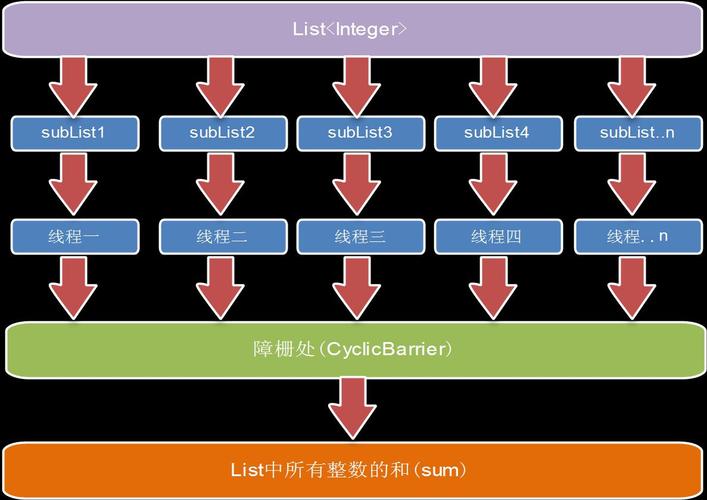
在现代软件开发中,sublist(子列表)是一个常见的概念,它指的是在一个较大的列表中划分出来的一个较小的、有序的元素集,Sublists可以用于多种编程和数据处理场景,比如数据切片、索引定位、搜索优化等。
Sublist的定义与特点
Sublist通常定义为原始列表中的一个连续部分,包含从某个起始索引开始到结束索引之前的所有元素,给定一个列表[1, 2, 3, 4, 5],其一个可能的sublist是[2, 3, 4],Sublist的特点包括:
连续性:sublist中的元素在原始列表中是连续出现的。
有序性:sublist保持了原始列表中元素的相对顺序。
边界明确:每个sublist都有明确的起始和结束位置。
Sublist的使用场景
数据切片
在处理大量数据时,我们经常只需要关注其中的一小部分,通过创建sublist,我们可以更高效地处理这些数据,而不必每次都遍历整个数据集,如果需要分析一个长列表中的特定区间内的数据,使用sublist将大大减少计算负担。
索引定位
在搜索算法中,sublist可以帮助缩小搜索范围,提高搜索效率,通过确定一个可能包含目标值的sublist,算法可以避免在整个列表中进行无效搜索。
搜索优化
在二分查找等高级搜索算法中,sublist的概念至关重要,算法首先选择一个sublist,然后根据比较结果调整搜索范围,直到找到目标值或确定其不存在。
Sublist的操作方法
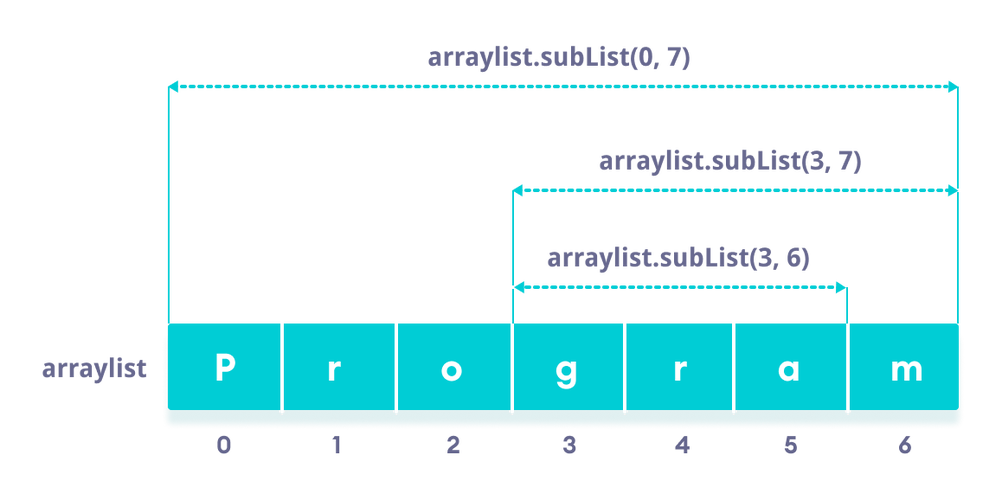
在大多数编程语言中,操作sublist的方法都很直观,以Python为例,可以使用切片操作符来创建sublist:
original_list = [1, 2, 3, 4, 5] sublist = original_list[1:4] # 结果是 [2, 3, 4]
在这个例子中,original_list[1:4]表示从索引1开始到索引4之前的子列表。
注意事项
虽然sublist提供了便利,但使用时也应注意以下几点:
性能考虑:在某些语言或实现中,sublist可能会复制原始列表中的元素,这可能导致额外的内存消耗和计算开销。
引用问题:有些情况下,sublist可能只是原始列表的一个引用,对sublist的修改可能会影响到原始列表。
边界条件:在使用sublist时,要特别注意边界条件,避免访问超出列表长度的索引。
相关问答FAQs
Q1: Sublist和原始列表有何不同?
A1: Sublist是从原始列表中提取的一个较小、连续的部分,它包含了原始列表中的一部分元素,不同于原始列表的是,sublist只包含有限的元素,并且这些元素在原始列表中是连续的。
Q2: 如何判断一个操作是否会影响原始列表?
A2: 这取决于编程语言和具体的实现方式,在一些语言中,如Python,切片操作会创建一个新列表,不会影响原始列表,而在其他语言或框架中,sublist可能只是原始列表的一个视图或引用,对其进行的任何修改都会反映在原始列表上,了解你所使用的编程语言的文档是判断这一点的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/914189.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复