

在当前的技术环境下,算子推荐列表配置成为了提高开发效率和优化性能的关键因素之一,将围绕【nodeType_算子推荐列表配置】这一主题进行详细的讨论与分析:
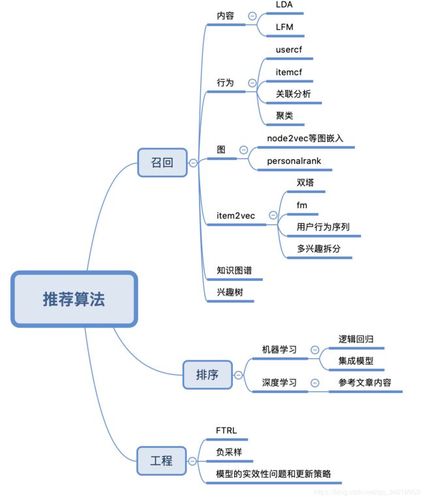

算子推荐列表配置
1、定义:算子推荐列表配置指的是通过配置文件,为不同类型的算子指定推荐的操作ID列表,这种配置方式可以有效地指导开发者选择合适的算子实现,优化数据处理流程。
2、配置示例:根据最新的更新(20210918),算子的推荐列表目前是通过配置文件写死的,配置文件中会定义一个推荐树,采用“key/value”的形式存储,key”代表算子类型,“value”则是该算子的推荐操作ID列表。
3、智能推荐系统:虽然当前主要是通过配置文件来硬编码推荐列表,但未来将支持智能推荐系统,这将进一步提高算子选择的灵活性和准确性。
算子工程目录结构
当命令执行完毕后,会在指定目录(或默认路径)下生成算子工程目录,以AddCustom算子为例,其目录结构包括算子实现的模板文件、编译脚本等,这为开发者提供了一套完整的工具和框架,以便快速开始算子的实现和优化工作。
算子实现模式设置
1、实现模式:算子的实现模式主要分为两种:high_precision(高精度)、high_performance(高性能),这两种模式各有侧重,分别适用于对精度或性能有特殊要求的场景。
2、关联参数:在设置算子实现模式时,需要配合使用op_select_implmode参数,通过optypelist_for_implmode参数设置的算子,将统一使用op_select_implmode参数指定的实现模式。
3、软件包下载与环境搭建:对于CANN(Compute Architecture for Neural Networks)算子开发,需要从昇腾社区下载对应的toolkit和算子开发包,根据实际的硬件架构(如X86_64或ARM),选择合适的版本进行下载和安装。
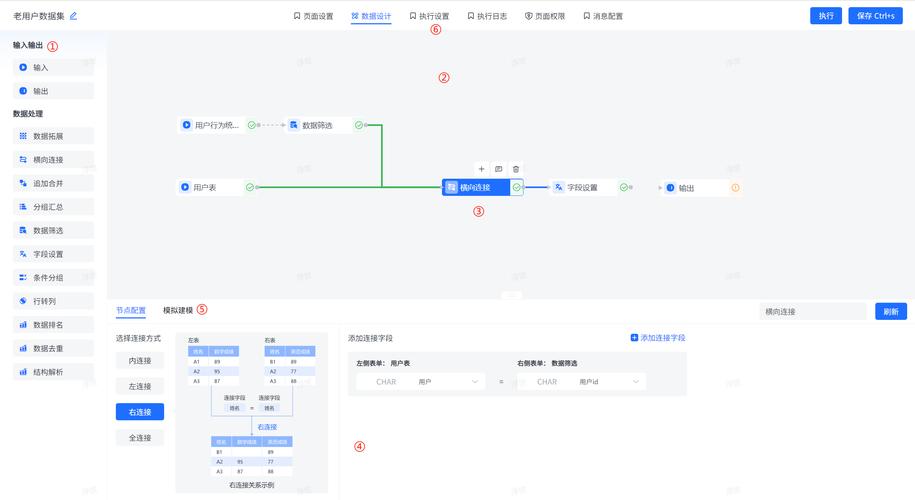
4、AI框架与CANN算子清单:AI框架算子基于ONNX、TensorFlow等框架定义,而CANN算子则是基于Ascend IR定义的单算子信息,了解这两者的差异和联系,有助于更好地进行算子选择和配置。
相关问题与解答
Q1: 如何选择合适的算子实现模式?
A1: 选择算子实现模式时,主要考虑应用场景的需求,如果应用对精度要求较高,应选择high_precision模式;若追求更高的运行性能,则应选择high_performance模式,还需考虑硬件环境的限制和兼容性。
Q2: 配置文件中的推荐树是如何工作的?
A2: 推荐树通过“key/value”的形式组织,key”是算子类型,“value”是推荐的操作ID列表,当开发者进行算子选择时,系统会根据当前的算子类型,在推荐树中查找对应的推荐操作ID列表,从而辅助开发者做出决策,未来智能推荐系统的加入,将使这一过程更加智能化和高效。
【nodeType_算子推荐列表配置】是一个涉及多个技术层面的复杂主题,包括算子推荐列表的配置、算子工程目录的结构、实现模式的设置以及相关资源的获取和环境搭建,通过对这些内容的深入了解和正确配置,可以显著提升开发效率和系统性能,希望本文能为从事相关工作的开发者提供有价值的参考和指导。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/914028.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复