


高可用(High Availability,简称HA)是确保系统持续运行和数据可靠性的关键策略之一,在Hadoop分布式文件系统(HDFS)中,NameNode的角色尤为重要,因为它维护了文件系统的元数据和命名空间,通过引入HA特性,HDFS能够更有效地防止单点故障,提高整个系统的鲁棒性和可靠性。
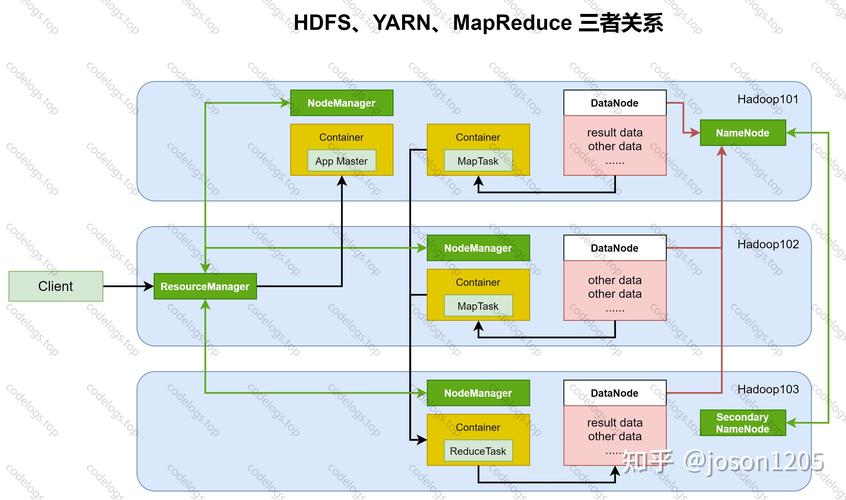

下面详细分析NameNode高可用性(HA)与HDFS其他组件的关系:
1、双NameNode架构
Active/Standby模式:HDFS集群中部署两个NameNode,一个处于Active状态,负责处理所有客户端的请求;另一个处于Standby状态,随时准备接管,这种架构确保了在任何给定时间,都有一个NameNode能够正常工作,即使其中一个失败。
2、故障转移机制
自动故障转移:当Active NameNode出现故障时,Standby NameNode会迅速接管其角色,这一过程通常通过ZooKeeper来协调,以确保元数据的一致性和操作的连续性。
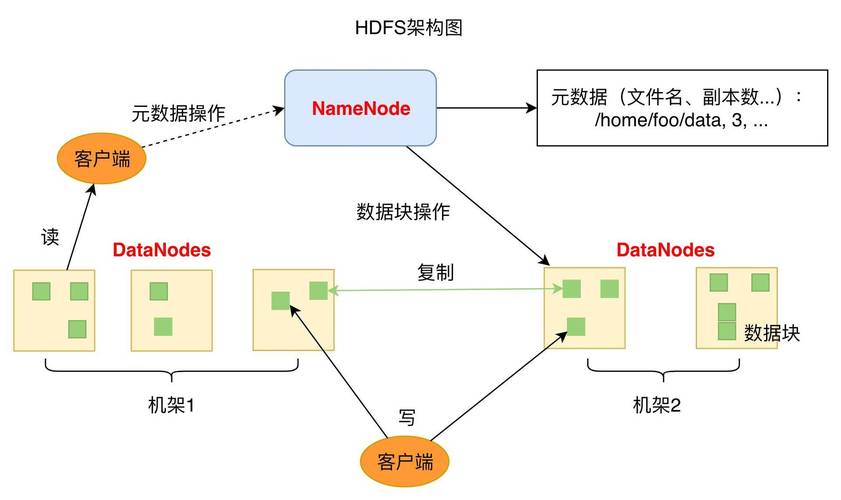
3、数据同步
编辑日志的共享存储:为了保持两个NameNode之间的数据状态一致,HDFS使用一组称为JournalNodes的独立进程来存储编辑日志,这些日志记录了所有对文件系统的修改操作,确保在故障转移后,新的Active Node可以准确地继续之前的状态。
4、系统监控与反馈
健康检查和状态更新:ZKFailoverController在HA架构中扮演着监督的角色,它通过健康检查来监控系统的总体状态,并在需要时触发故障转移过程,这保证了系统的高可用性和故障恢复能力。
5、与YARN的比较

相似但不同:虽然HDFS和YARN的HA方案在设计上有相似之处,但由于NameNode对数据存储和一致性的要求更高,HDFS的HA实现更为复杂和严格。
提出两个与本文相关的问题,并尝试解答:
1、如何判断NameNode是否需要故障转移?
答:可以通过监控工具或脚本定期检查NameNode的健康状态,如响应时间和系统负载,一旦Active NameNode未能响应或性能严重下降,即可触发故障转移。
2、NameNode HA是否会影响HDFS的性能?
答:虽然双NameNode架构增加了系统复杂性,可能会略微影响性能(同步编辑日志需要额外的资源),但这种影响通常被高可用性和故障恢复的优势所抵消,合理的资源分配和优化可以最小化这种影响。
NameNode的高可用性(HA)是HDFS中一个至关重要的组件,它通过双节点架构、故障转移机制以及数据同步等技术手段确保了系统的稳定运行和数据的完整性,了解这些组件的相互作用有助于更好地管理和优化Hadoop集群的性能和可靠性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/913857.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复