


Nutch是一个开源的网络搜索引擎,它基于Java实现,并且使用了Apache Hadoop的MapReduce编程模型来处理和索引大量的网页数据,在Nutch中,MapReduce任务被用于执行网络爬虫、文档解析、链接分析以及建立索引等操作,下面我将详细介绍Nutch中的MapReduce作业,并给出相应的例子。
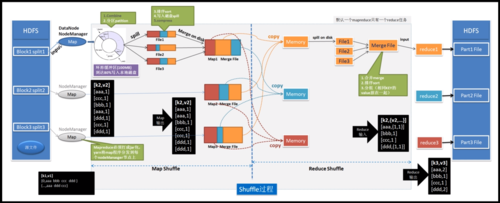

Nutch的MapReduce作业
1. 网络爬虫 (Crawling)
在Nutch中,网络爬虫是第一个步骤,它使用MapReduce作业来发现新的网页并将其抓取下来,这个过程分为两个阶段:生成(generate)和抓取(fetch)。
生成阶段: Map任务产生待抓取URL列表。
抓取阶段: Reduce任务下载这些URL指向的网页内容。
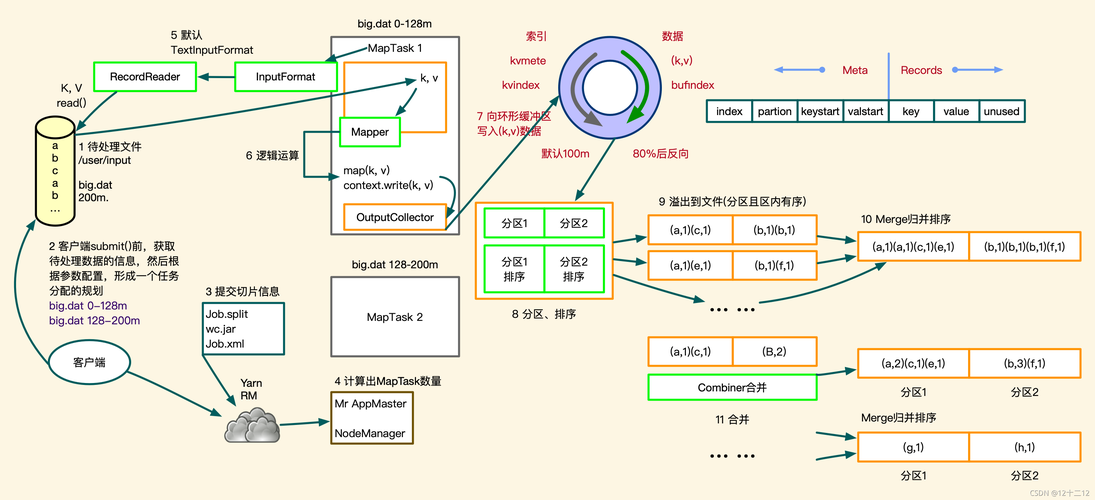
2. 文档解析 (Parsing)
抓取到的网页需要被解析成结构化的文本,以便后续处理,解析过程同样通过MapReduce来实现,其中Map任务负责解析单个网页,而Reduce任务则对解析结果进行整合。
3. 链接分析 (Link Analysis)
链接分析是评估网页重要性的过程,通常采用算法如PageRank,在Nutch中,链接分析也通过MapReduce来完成。
Map阶段: 计算单个网页的评分。
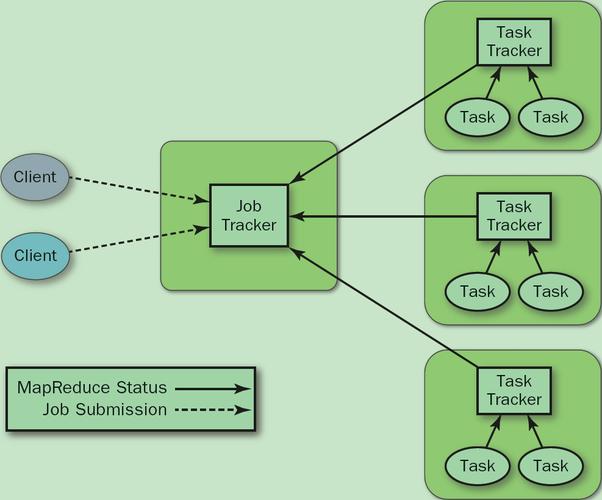
Reduce阶段: 汇总所有网页的评分,更新全局的链接数据库。
4. 索引建立 (Indexing)
最后一步是将抓取并解析后的文档建立索引,以便用户能够快速检索,索引建立也使用MapReduce,其中Map任务创建文档的倒排索引,Reduce任务合并这些索引。
Nutch MapReduce示例
假设我们有一个简化的MapReduce作业,用于计算每个网页的单词数,这个作业可以作为索引建立的一部分。
Map阶段
输入是抓取到的网页集合,输出是<单词, 出现次数>键值对。
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split("\s+");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
} Reduce阶段
输入是Map阶段的输出,输出是每个单词的总出现次数。
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} 相关问题与解答
问题1: Nutch中使用MapReduce的主要优点是什么?
答: Nutch使用MapReduce的主要优点是能够有效地处理和存储大量分布式数据,Hadoop的MapReduce框架允许Nutch并行处理多个任务,从而加速了网络爬虫、文档解析、链接分析和索引建立等过程,它还提供了容错机制,确保即使在硬件故障的情况下也能保证数据的完整性。
问题2: 如果我想自定义Nutch的MapReduce作业,我应该如何开始?
答: 要自定义Nutch的MapReduce作业,你需要首先了解Hadoop MapReduce编程模型的基础,你可以继承Mapper或Reducer类来创建自己的Map和Reduce函数,在编写自定义代码时,确保遵循Nutch的API和数据模型,完成后,你需要将你的自定义作业集成到Nutch的工作流程中,并配置相应的参数来运行它。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/913332.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复