


自定义Flink Streaming作业


Flink流处理简介
Apache Flink是一个高效、分布式的数据处理框架,它支持批处理和流处理,在流处理模式下,Flink可以处理无限数据流,并实时地对数据进行转换和分析,Flink的核心优势在于其低延迟的处理能力和高吞吐量,以及能够提供精确一次(exactlyonce)的状态一致性保证。
创建自定义Flink Streaming作业步骤
1、环境准备:
安装Java开发环境(JDK)。
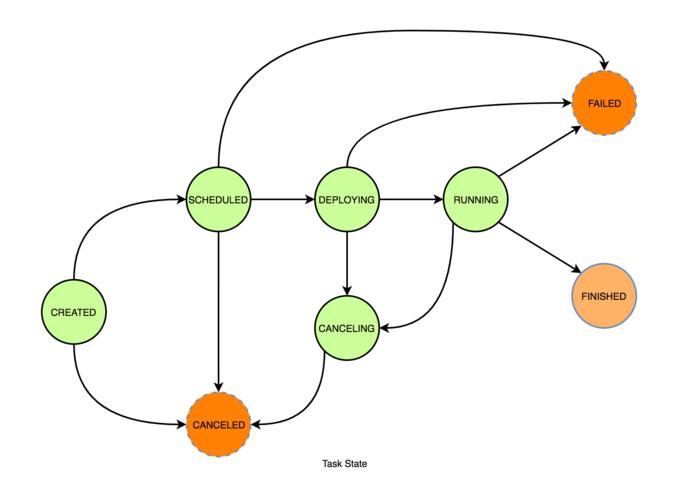
下载并配置Apache Flink。
设置IDE(如IntelliJ IDEA或Eclipse)。
2、搭建项目结构:
使用Maven或Gradle创建新的项目。
添加Flink依赖到项目中。
3、编写代码:
定义数据源(Source)。
实现数据处理逻辑(Transformations)。
定义数据汇(Sink)。
4、作业优化与调试:
配置并行度以优化性能。
使用Flink的Web界面监控作业状态。
调试和测试作业逻辑。
5、部署与运行:
将作业打包为JAR文件。
提交作业到Flink集群。
监控作业运行情况并调整配置。
示例:单词计数作业
下面是一个简化的单词计数Flink Streaming作业的代码示例:
// 引入必要的包
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 连接数据源
DataStream<String> text = env.socketTextStream("localhost", 9000);
// 数据转换
DataStream<WordWithCount> wordCounts = text
.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String value, Collector<WordWithCount> out) {
for (String word : value.split("\W+")) {
out.collect(new WordWithCount(word, 1));
}
}
})
.keyBy("word")
.sum("count");
// 输出结果
wordCounts.print().setParallelism(1);
// 执行作业
env.execute("Streaming WordCount");
}
// 定义单词计数的数据类型
public static class WordWithCount {
public String word;
public long count;
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + ''' +
", count=" + count +
'}';
}
}
} 问题与解答栏目
Q1: Flink Streaming作业中如何保证数据不丢失?
A1: Flink通过检查点(checkpoint)机制来保证数据不丢失,检查点是系统状态的一个快照,定期保存到持久化存储中,如果作业失败,可以从最近的检查点恢复,确保正确配置检查点间隔和持久化存储是防止数据丢失的关键。
Q2: 如果Flink作业的性能不佳,有哪些常见的调优方法?
A2: Flink作业的性能可以通过以下几种方式进行调优:
调整并行度:根据集群资源合理设置任务的并行度。
网络调优:优化数据传输序列化方式,减少数据传输大小。
内存管理:适当调整Flink的内存配置,避免频繁的GC。
缓存策略:对于热点数据,可以使用缓存来提高读取效率。
状态后端选择:根据作业特点选择合适的状态后端(如RocksDB)。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/913320.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复