


内存数据库与MapReduce技术是大数据领域中的两个重要概念,在处理大规模数据集时,内存数据库和MapReduce技术各自有其独特的优势和应用场景,本文将探讨这两种技术的基本概念、特点、以及如何结合使用它们来优化大数据处理。
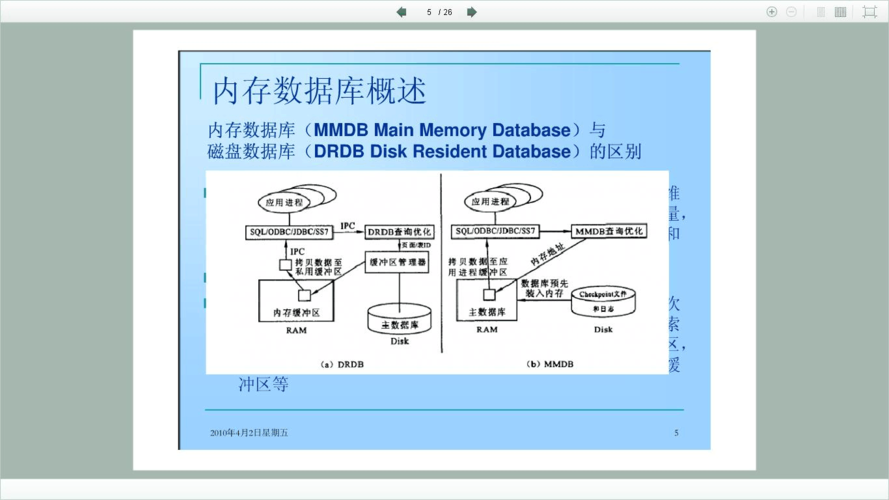

内存数据库
内存数据库是一种将数据存储在RAM(随机访问内存)中的数据库管理系统,与传统的磁盘驻留数据库相比,内存数据库能够提供更快的数据读写速度,这是因为内存访问速度远高于磁盘访问速度。
特点
高速读写:内存数据库能够实现微秒级的读写操作。
低延迟:由于数据直接在RAM中处理,系统响应时间大大缩短。
高吞吐量:可以处理大量并发请求,适用于实时数据分析和高频交易系统。
应用场景
金融行业的高频交易系统。
电信行业的呼叫数据处理。
互联网服务的实时推荐系统。
MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它通过“映射(Map)”和“归约(Reduce)”两个阶段来完成数据处理任务。
特点
分布式计算:可以在多台计算机上并行处理数据。
容错性:能够自动处理节点故障,保证计算任务的完成。
扩展性:可以根据数据量和计算需求动态增减计算资源。
应用场景
大数据分析。
日志文件处理。
机器学习和数据挖掘。
结合内存数据库和MapReduce
内存数据库和MapReduce的结合使用可以为大数据处理带来显著的性能提升,在MapReduce的Map阶段之前,可以先将数据加载到内存数据库中,以加快数据的读取速度,而在Reduce阶段,可以将中间结果暂存于内存数据库,减少磁盘I/O开销,提高处理效率。
结合使用的优势
加速数据处理:内存数据库的高速读写能力可以显著减少MapReduce作业的执行时间。
提高系统稳定性:内存数据库的高可用性和故障恢复机制可以增强整个大数据处理系统的可靠性。
实施策略
数据预热:在MapReduce作业开始前,预先将数据加载到内存数据库中。
中间结果缓存:在Map和Reduce阶段之间,使用内存数据库缓存中间结果。
结果持久化:将最终结果从内存数据库同步到持久化存储中,以防数据丢失。
相关问题与解答
Q1: 内存数据库是否适合所有类型的大数据应用?
A1: 不是,内存数据库虽然速度快,但成本较高,且数据量受到物理内存大小的限制,对于不需要极高性能或数据量超出内存容量的场景,传统的磁盘驻留数据库或其他大数据技术可能更为合适。
Q2: MapReduce是否过时了?
A2: MapReduce仍然是处理大规模数据集的有效工具之一,尤其适用于批处理任务,随着新的大数据处理框架如Apache Spark的出现,MapReduce的使用率有所下降,因为Spark等框架提供了更高效的内存计算能力和更丰富的数据处理功能,不过,MapReduce在某些特定场景下仍然有其独特的优势和适用性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/911827.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复