


MapReduce中的分片与变更


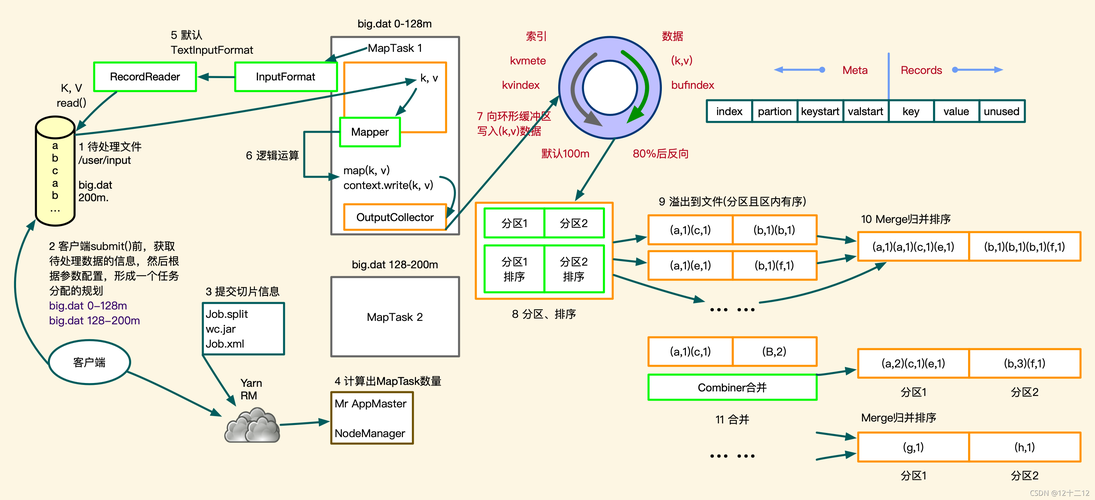
MapReduce是大规模数据处理的利器,其核心思想在于“分而治之”,在MapReduce作业提交之前,原始数据会经过一个划分处理,形成逻辑上等长的数据对象,这些对象被称为输入分片(inputSplit),每个分片都会由一个单独的MapTask处理,负责执行用户自定义的映射函数,这种预处理步骤,不仅关乎如何高效地分配任务,也直接影响作业的执行效率和资源的利用情况,本文将深入探讨MapReduce中分片的概念、重要性以及如何进行分片的变更。
1、分片的基本概念
定义与作用:分片,即输入分片(InputSplit),是MapReduce作业中数据预处理的基本单位,每个分片会创建一个MapTask,负责处理分片内的数据,通过这种方式,一个大数据集被有效地分割成多个小数据集,每个小数据集可以独立并行处理。
分片与MapTask的关系:分片的数量直接决定了MapTask的数量,理想情况下,每个分片应由一个单独的MapTask处理,以实现并行计算。
分片大小的决定因素:分片的大小通常与HDFS的blockSize相等,这个值默认为128MB,如果文件使用了不支持切分的压缩算法,如Gzip或Snappy,则不管文件大小如何,都只能作为一个分片处理。
2、分片的逻辑与算法
动态分片逻辑:分片逻辑基于一个基准值(splitSize),当文件大小超过该值的1.1倍时,系统会进行进一步的分片处理,直至文件大小低于基准值的1.1倍,这一逻辑确保了数据处理的高效性和灵活性。

源码解读:从源码角度来看,分片操作是MapReduce过程的起始输入部分,涉及对目标文件夹中的文件进行切分处理。
分区、排序与分组:分片与MapReduce中其他关键步骤——分区、排序和分组有着直接的联系,每个步骤都是数据处理的一个环节,共同构成了完整的数据处理流程。
3、变更分片的影响与策略
影响分析:变更分片可能会影响作业的执行效率和资源使用率,不合适的分片可能导致数据处理不均衡,从而影响整体性能。
优化策略:合理调整splitSize的大小,可以根据实际情况和硬件资源来优化数据处理的效率,考虑数据的本地性,减少数据在网络中的传输可以显著提升性能。
应对不同数据类型的策略:针对不同的数据类型和访问模式,选择合适的分片策略,例如对于序列化数据和文本数据采用不同的分片方法。
在深入了解了MapReduce中分片的基本概念、逻辑与变更策略后,我们可以进一步讨论一些相关的实用问题,以便更好地理解和应用这一技术。
相关问答FAQs
如何根据实际需求调整分片大小?
基建议:
根据集群的实际配置和数据的特性进行调整,比如对于高压缩率的数据文件,适当增加分片大小可以减少任务启动的开销。
考虑到数据的本地性,尽量让分片的大小与HDFS的block大小保持一致,这有助于提高数据处理的效率。
分片数量是否越多越好?
具体分析:
更多的分片意味着更多的MapTask,这可能会导致管理开销增大,而不一定能有效提升处理速度。
适量的分片能够确保负载均衡,但过多的分片可能会引入不必要的复杂性和调度开销,理想的分片数量应当根据实际的数据集大小和集群的处理能力来决定。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/910341.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复