


通义千问模型介绍

探索大语言模型的力量与应用
1、
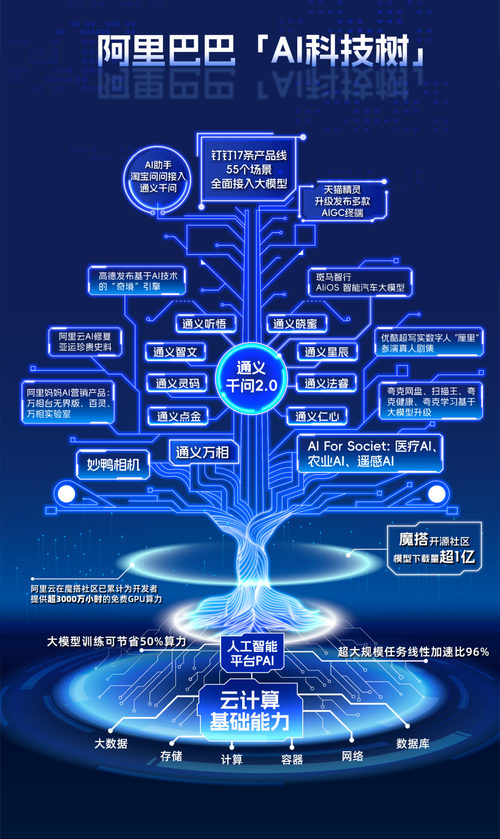
通义千问系列模型由阿里云研发,基于Transformer架构,旨在理解和分析自然语言,服务不同领域和任务。
Qwen7B是该系列的一员,具备70亿参数规模,展示了其处理复杂文本和任务的能力。
2、模型系列与参数规模
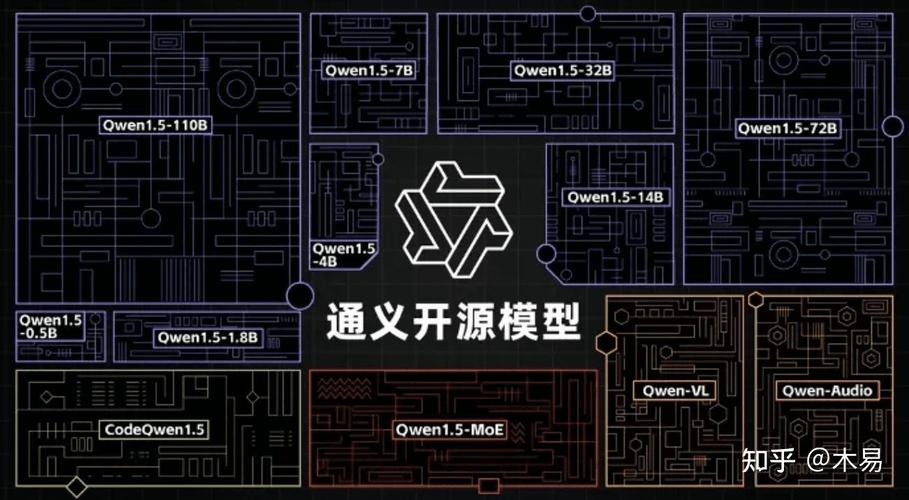
千问模型系列包括四款基础开源模型,涵盖18亿至720亿参数量,满足不同级别的计算和性能需求。
3、预训练与微调
在超大规模预训练数据上进行训练,数据类型多样,确保模型具有广泛的知识覆盖和理解能力。
通过针对性的微调和优化,模型能够适应特定场景的需求,提高任务执行的精准度和效率。
4、多模态与跨语言能力
除了文本处理,通义千问还支持多模态交互,如图像和语音,使其能在更广泛的应用场景中发挥作用。
跨语言模型的加入使得其能够支持多语言交互,为国际化需求提供了可能。
5、性能比较与评价
在国内外的大模型中,Qwen72B展现了优异的理科和文科测试成绩,尽管与顶尖模型存在差距,但仍属于领先水平。

6、实际应用与API服务
通过DashScope等平台,开发者可以便捷地接入千问模型的API服务,推动应用开发和科研工作的进展。
7、未来展望
随着技术的进一步发展和优化,通义千问有望在更多领域展现其价值,尤其是在精确指令遵循和跨领域适应性方面的进步。
通义千问模型不仅在参数规模和预训练技术上有所突破,其在多模态交互和跨语言功能上的扩展也极大地增强了其实用性和灵活性,作为开发者或科研人员,了解并利用这些模型的特性能够显著提升工作效率和研究成果的创新度。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/909297.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复