


在大数据时代,随着数据量的飞速增长,传统的数据加载方式已经无法满足高效、快速的数据存储需求,HBase作为一个广泛应用于NoSQL数据库领域的分布式存储系统,提供了BulkLoad这一高效的数据批量加载工具,它允许用户将大量数据高效地导入到HBase表中,本文将深入探讨仅有mapper的MapReduce作业如何提升HBase BulkLoad工具的批量加载效率。
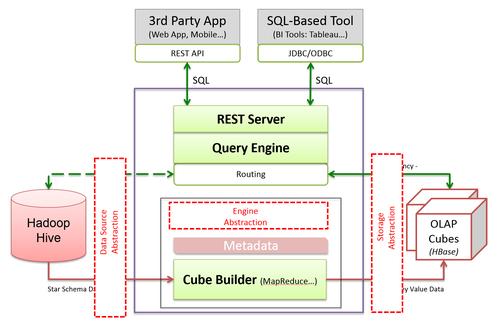

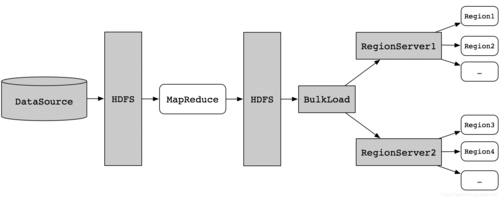
批量加载的基本机制是通过MapReduce作业直接生成符合HBase内部数据格式的文件,这些文件是StoreFiles,可以直接被加载到正在运行的HBase集群中,相比于直接使用HBase的API进行数据写入,批量加载可以节约大量的CPU和网络资源,这是因为,批量加载减少了客户端与HBase服务器之间的交互次数,降低了数据传输时的开销。
让我们详细了解批量加载操作的场景和步骤,在执行批量加载任务时,需要指定一个输出路径参数“Dimporttsv.bulk.output”,该参数决定了生成的StoreFiles文件的存放位置,这意味着,在进行批量加载之前,必须规划好数据的存放策略以避免潜在的文件管理混乱。
使用MapReduce进行数据预处理是提高加载效率的关键步骤,在这一过程中,原始数据被转换为HBase内部数据格式,然后写入HDFS的临时目录中,此步骤确保了数据在导入HBase之前已经是最佳格式,从而缩短了数据的网络传输时间和解析时间。
针对华为云MapReduce服务的用户,使用BulkLoad方式向HBase中批量导入本地数据的实践也表明,在首次数据加载时,这种方式能极大提高写入效率并降低对Region Server节点的写入压力,这说明了MapReduce结合BulkLoad不仅适用于通用的Hadoop环境,还适配于特定的云服务平台,展现了其广泛的适应性和高效性。
在使用BulkLoad的过程中,一些常见的问题也需要被关注,数据的预处理和格式转换可能会占用额外的时间和资源,这要求开发者在设计MapReduce作业时需要进行细致的规划和优化,同样,对于数据的有效性和完整性的验证也是不可或缺的步骤,确保导入HBase的数据是准确无误的。
通过合理配置MapReduce作业,充分利用BulkLoad工具的特性,可以显著提升HBase的数据加载效率,这不仅为数据处理带来了便捷,也为数据的高效存储和管理奠定了基础,在此背景下,仅有mapper的MapReduce作业通过减少数据的序列化和反序列化过程,直接生成可供HBase使用的StoreFiles,成为了提升HBase BulkLoad工具批量加载效率的有效手段。
我们将通过相关问答FAQs部分,进一步解答有关使用BulkLoad和MapReduce作业提升效率的常见疑问,以期提供更加全面的视角和实用的建议。
相关问答FAQs
Q1: 为什么使用BulkLoad比直接使用HBase API更有效率?
A1: BulkLoad之所有更有效率,是因为它减少了客户端与HBase服务器之间的多次交互,通过网络发送的是经过优化的StoreFiles文件,而不是单个行键值对,这种方法降低了网络通信的开销,并且由于数据已经预先格式化,减轻了HBase服务器端的处理负担。
Q2: 如何确保在使用BulkLoad时数据的准确性和完整性?
A2: 确保数据准确性和完整性的关键在于数据预处理阶段,在MapReduce作业中加入数据校验和清洗的步骤,排除不合规或错误的数据记录,在数据正式加载到HBase前,可以先进行小范围的测试,验证数据是否能正确导入以及是否符合业务逻辑要求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/908747.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复