


在当前的大数据时代,有效地从海量数据中提取出有用的信息是企业和技术从业者面临的一大挑战,MapReduce模型提供了一种解决方案,它能够通过分布式处理大规模数据集,尤其在处理非结构化数据方面表现出强大的能力,本文旨在深入探讨如何利用MapReduce进行特定数据的提取作业,并在此过程中保证内容的准确性和全面性,具体如下:


1、搭建实验环境
准备数据源:在进行MapReduce编程之前,需要准备好数据源,实验数据可以存储在文本文件中,例如机票销售记录等,并上传到分布式文件系统HDFS上。
实验目的和内容确定:明确实验的目的,如掌握使用MapReduce进行数据分析,以及具体的实验内容,包括使用的数据集和预期的数据处理流程。
2、编程模型解析
核心思想理解:MapReduce的核心是将大数据处理任务分解为Map和Reduce两个步骤,其中Map阶段负责分解数据,而Reduce阶段负责对数据进行聚合。
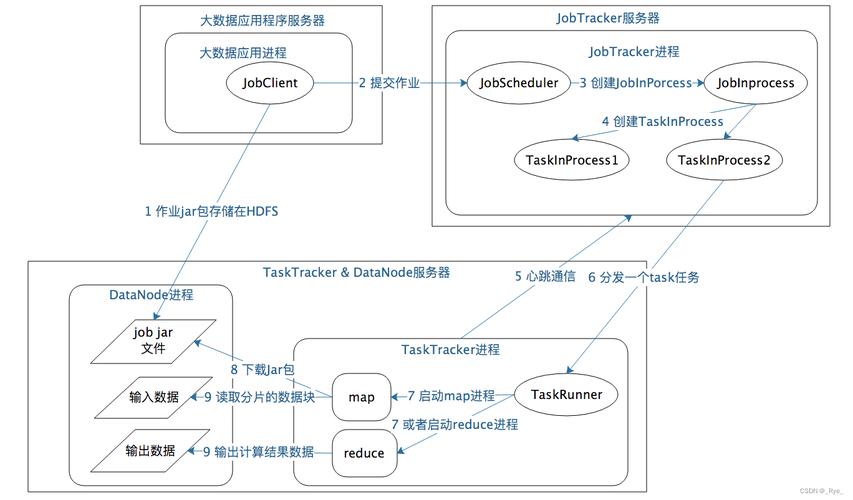
Mapper和Reducer的作用:Mapper负责接收原始数据并进行转换,输出键值对;Reducer则处理这些键值对,进行聚合操作,并产生最终结果。
3、编程实践
FlowBean类定义:首先需要定义一个序列化Bean对象用于数据传输,例如FlowBean,它实现了WritableComparable接口以允许数据的写入和比较。
编写Mapper和Reducer类:根据需求实现Mapper类(如FlowCountMapper)和Reducer类(如FlowCountReducer),它们分别负责数据的映射和归约操作。
4、数据处理流程梳理
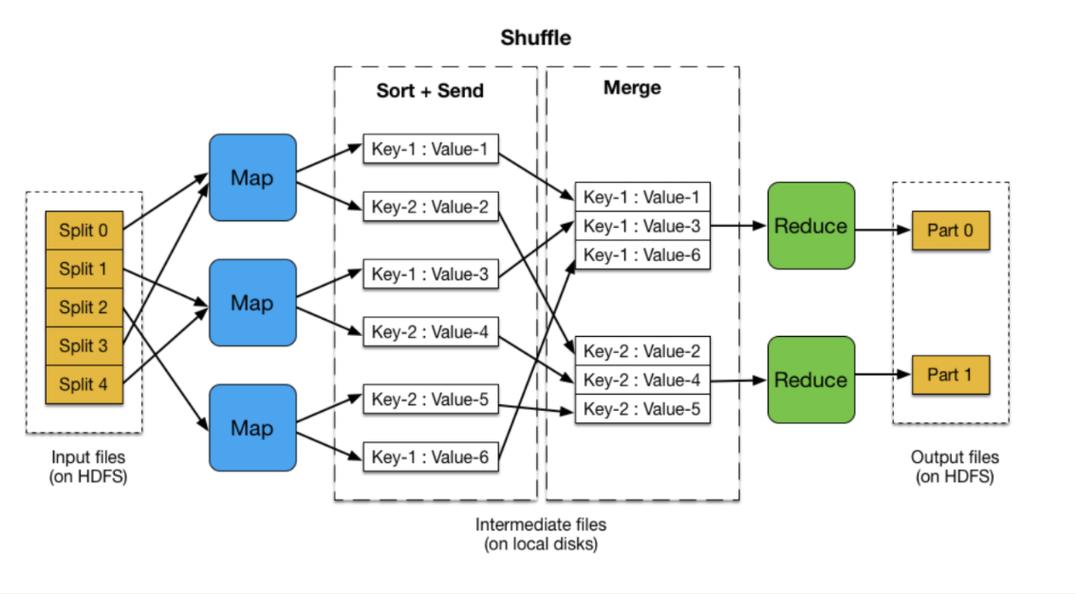
数据分割和读取:输入数据被MapReduce框架分割成片,每个分片由单独的Mapper处理,InputFormat类负责数据分片的逻辑划分,与HDFS的数据块物理划分相区别。
键值对流转分析:在整个MapReduce程序中,数据都以键值对的形式流转,因此必须仔细设计每个阶段的输入输出键值对类型,并考虑数据排序和分组机制。
5、复杂问题解决策略
扩展InputFormat子类:为了适应不同类型的数据处理需求,可以通过扩展InputFormat类来自定义数据分片和读取逻辑。
优化数据处理逻辑:通过对MapReduce程序性能分析和调优,如合理设置数据分片大小,可以有效提升数据处理效率。
6、结果验证与调整
代码调试:运行编写好的MapReduce作业,通过查看日志和输出结果验证程序的正确性。
性能优化:根据作业运行情况,调整MapReduce配置参数或优化代码逻辑,以提高数据处理速度和准确度。
值得注意的操作细节包括确保数据源的质量,以及在编程时关注数据处理的完整性和逻辑准确性,还需留意的是,MapReduce作业的优化不仅仅在代码层面,还包括合理配置硬件资源和集群设置。
通过上述详细的步骤和策略,可以高效地完成MapReduce特定的数据提取作业,现在提供的相关FAQs内容如下:
FAQs
1. MapReduce程序中数据是如何流动的?
在MapReduce程序中,数据以键值对的形式进行流动,Map阶段读取原始数据并转换为键值对输出,之后可能会经过混洗(Shuffle)和排序(Sort)过程,Reduce阶段将具有相同键的值集合在一起进行处理,生成最终结果。
2. 如果在MapReduce作业中遇到性能瓶颈,应该如何优化?
遇到性能瓶颈时,可以尝试以下几种优化策略:增加Mapper和Reducer的数量以平衡负载、调整数据分片大小以匹配不同数据集的特点、优化数据序列化和传输方式减少开销、以及合理配置集群资源管理策略。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/907889.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复