


在现代数据库管理中,SQL语言以其强大的数据处理能力被广泛使用,分组(GROUP BY)是SQL中的一种强大功能,它允许用户对数据进行集合和汇总,从而进行复杂的数据分析,本文旨在全面介绍SQL中的分组概念、用法及其与其他SQL子句的联合使用方法,并通过示例加深理解。

基本语法和概念
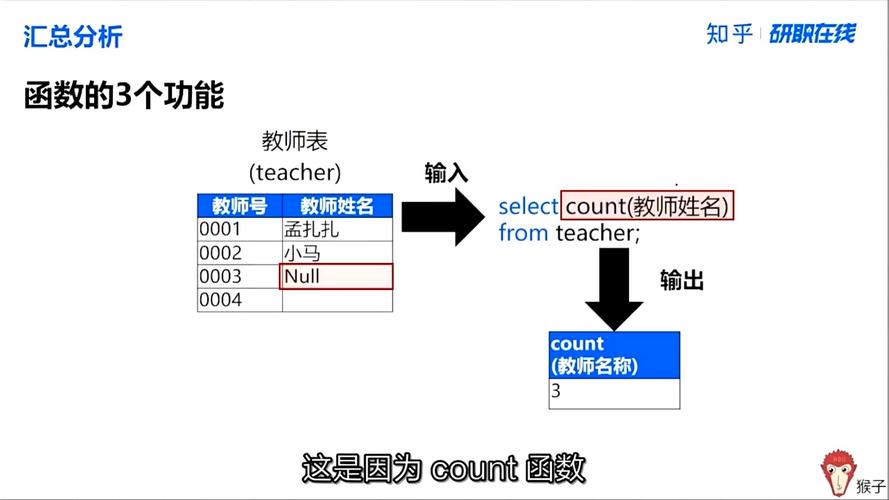
在SQL中,GROUP BY语句用于将具有相同数据的行分组在一起,通常与聚合函数(如SUM、COUNT、MAX、MIN、AVG等)一起使用,其基础语法为:
SELECT column_name, aggregate_function(column_name) FROM table_name GROUP BY column_name;
这里的column_name是要进行分组的列名,而aggregate_function则是对分组后的数据进行操作的聚合函数,如果我们有一个订单表并且想要根据客户ID来统计每个客户的总订单金额,可以使用如下查询:
SELECT customer_id, SUM(order_amount) FROM orders GROUP BY customer_id;
这个查询将订单表(orders)中的记录按照customer_id字段进行分组,并计算每组的订单金额总和。
高级应用与联合使用
结合Having子句
虽然WHERE子句用于过滤行,但HAVING子句是在分组后的数据上进行条件筛选的,这在需要进行基于聚合结果的筛选时非常有用。
SELECT product_category, COUNT(*) FROM products GROUP BY product_category HAVING COUNT(*) > 10;
此查询将产品表(products)按产品类别分组,并只返回那些类别下产品数量超过10的组。
与Order By的联合
GROUP BY和ORDER BY可以一起使用来对分组结果进行排序,这对于展示数据特别有用,尤其是在处理大量数据时。
SELECT customer_id, COUNT(*) FROM orders GROUP BY customer_id ORDER BY COUNT(*) DESC;
这个查询首先按客户ID分组,然后按订单数量降序排列。
使用Compute子句
在某些SQL实现中,COMPUTE子句提供了一种在结果集上执行聚合操作的方式,它可以用作GROUP BY的替代或补充,如果需要在每个分组后添加一个总计行,可以使用COMPUTE。
实际应用场景
在实际业务中,GROUP BY广泛应用于销售数据分析、库存管理、客户行为分析等领域,通过分组技术,我们可以快速得出每个销售区域的产品销量,从而对市场策略进行调整。
注意事项与细节
在使用GROUP BY时,选择正确的列进行分组是关键,不当的分组可能导致数据过度聚合或不充分聚合。
所有的聚合函数如SUM(),COUNT()等,必须在包含GROUP BY的查询中与GROUP BY列直接或间接相关联。
在使用GROUP BY时,应避免使用不必要的列,以减少数据库的负担和提高查询效率。
随着技术的发展,对数据处理的需求日益增加,掌握SQL的分组技术对于数据分析师和数据库管理员而言极为重要,通过有效地使用GROUP BY语句,可以大幅增强数据处理的能力,为企业决策提供强有力的数据支持。
相关问答FAQs
Q1: 如何在SQL中使用GROUP BY进行多列分组?
A1: 在SQL中,可以通过在GROUP BY子句中列出多个列名来实现多列分组,如果我们想根据产品类别和客户ID对订单进行分组,可以使用以下查询:
SELECT product_category, customer_id, COUNT(*) FROM orders GROUP BY product_category, customer_id;
这将会对每一种产品类别和每一个客户的组合进行分组,并计算每组的订单数。
Q2: 使用GROUP BY时有哪些常见的错误应该避免?
A2: 在使用GROUP BY时,有几个常见错误需要避免:
遗漏必要的聚合函数:在SELECT语句中,除了GROUP BY的列之外的所有列都应该是聚合函数的参数。
错误的列引用:确保所有非聚合列都被包含在GROUP BY子句中。
混淆WHERE和HAVING:WHERE用于过滤行,而HAVING用于过滤聚合结果,确保正确使用这两个子句以达到预期的效果。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/907691.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复