

深入探索MapReduce与HBase的整合操作

HBase作为一款开源的非关系型分布式数据库,因其存储海量数据的能力而被企业广泛使用,而提到数据处理,不得不提的是MapReduce,这一模型在处理大数据时展现出了巨大的优势,本文将详细阐述如何通过MapReduce来操作HBase中的数据,旨在为开发者提供一份实践指南。
环境搭建与配置
要实现MapReduce对HBase的操作,首先需要准备合适的实验环境,实验环境基于Centos 7.5操作系统,使用的软件包括Apache Hadoop 2.7.3、Apache Zookeeper 3.4.10、Eclipse Neon以及Apache HBase,这些组件相互协作,共同构成了一个强大的数据处理平台,具体环境配置方法可以参考相关技术文档和官方指南,确保各个服务正确安装并能够顺利运行。
HBase与MapReduce的结合
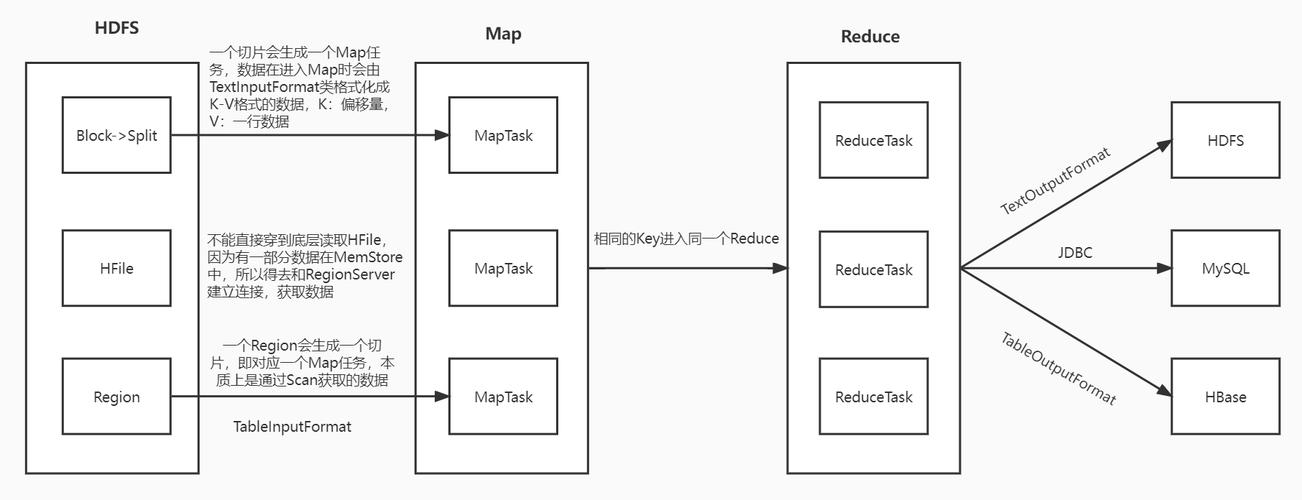
MapReduce框架通过将任务分配到多个节点上并行处理大规模数据集,有效提高了数据处理的速度,对于存储在HBase中的表而言,可以将其视作MapReduce作业的输入源(Source)或输出目标(Sink),HBase提供了TableInputFormat和TableOutputFormat两种API,方便开发者将HBase表作为数据的输入和输出资源,这种设计使得开发者无需关注底层细节,便可实现复杂的数据处理逻辑。
基本操作流程
使用Hadoop MapReduce框架提供的API进行编程时,开发者需要关注的核心在于Mapper和Reducer的编写,Mapper负责读取HBase表中的记录,并将每条记录转换为键值对;Reducer则根据键进行聚合,并可以将结果写回HBase,这一系列过程涉及到数据的读取、处理和写入,是实现复杂数据操作的基础。
实操案例
为了加深理解,以下列举两个具体的案例:
数据导入:将本地文件系统中的数据通过MapReduce作业导入到HBase表中,此过程中,Mapper读取文件中的记录,经过处理后,通过Reducer将数据写入指定的HBase表。
数据复制:将一张HBase表中的数据拷贝到另一张表中,这个过程中,Mapper读取源表的数据,而Reducer将这些数据写入目标表。
注意事项
确保所有服务(包括Hadoop、Zookeeper和HBase)均正确配置和运行。
在进行数据处理时,合理设计Mapper和Reducer的逻辑,以提高效率。
注意数据格式和编码问题,避免因格式不匹配导致的错误。
优化建议
合理设置MapReduce作业的并发数,根据集群的实际能力调整。
对HBase表的设计进行优化,如合理选择行键,以提高查询效率。
监控作业运行状态,及时调整策略以应对可能的性能瓶颈。
通过上述步骤和案例的介绍,可以看出使用MapReduce操作HBase不仅可行,而且十分高效,我们将探讨一些常见问题及解决方案,以帮助读者更好地理解和应用这一技术。
相关问答FAQs:
Q1: 如何处理HBase中数据与MapReduce作业之间的数据格式不匹配问题?
A1: 在MapReduce作业中,可以通过自定义的Serializer和Deserializer类来转换数据格式,这样,在数据从HBase读出或写入时,可以自动转换成适合处理的格式。
Q2: 如何提高MapReduce操作HBase的效率?
A2: 可以从以下几个方面入手:优化Mapper和Reducer的逻辑,减少不必要的计算;合理设置MapReduce作业的内存和CPU资源配额;对HBase表进行预分区,减少Region的数量;使用批处理方式写入HBase,减少网络开销。
通过以上内容的介绍,我们了解了如何使用MapReduce操作HBase数据,并通过案例和FAQs加深了理解,希望这些信息对正在使用或打算使用MapReduce和HBase的开发者有所帮助。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/907442.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复