


【mapreduce 决策树_决策树回归】
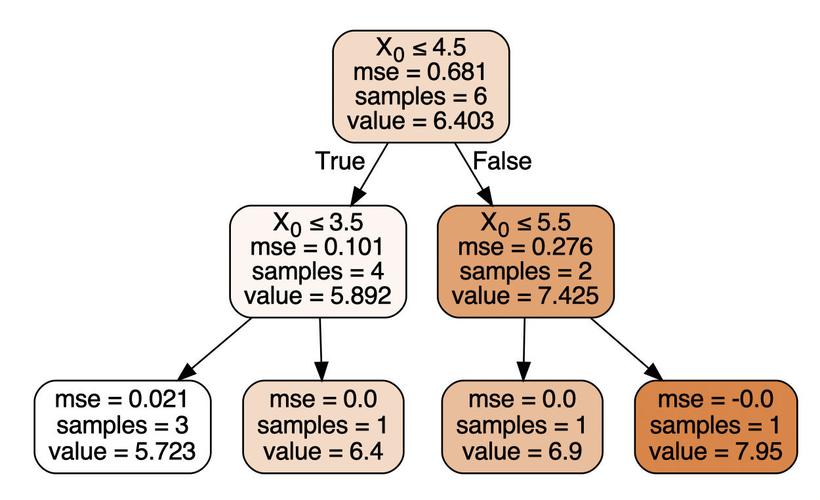

决策树回归作为一种预测连续型变量的机器学习方法,在大数据领域中通过MapReduce编程模型得到广泛应用,该模型能够在大规模数据集上并行处理数据,构建决策树模型以预测目标变量,决策树回归的核心思想是通过递归划分数据集,使得每个子集中的数据尽可能与真实的连续型变量值接近。
基于C45决策树算法实现对应的Mapper算子,在MapReduce框架下,Mapper算子负责读取原始数据,并筛选出有用的列信息,如日期、地区、严重程度等,对数据进行初步的处理,在此阶段,可以通过Spark或MapReduce进行数据清洗和筛选,为决策树的构建准备数据。
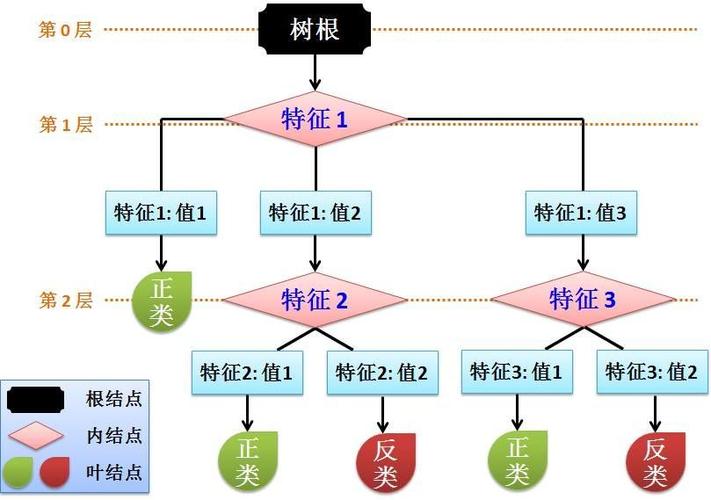
决策树回归的构建过程主要包括选择最佳属性/特征来划分数据,这一过程是通过计算不同属性对输出值的影响来完成的,目的是使每个子集内部的输出值尽可能相似,构建决策树回归模型时,需要考虑如何评估属性的重要性以及如何确定划分的属性标准,还要决定树的深度以及如何处理过拟合问题。
地区差异也是一个重要的分析维度,根据车祸数据的地理位置信息,可以计算出各地区的车祸发生率,进而分析哪些外界环境变量对车祸严重程度有显著影响,这些信息有助于理解不同地区车祸发生的潜在原因,并为制定针对性预防措施提供依据。
MapReduce下的决策树回归结合了大数据处理能力与机器学习的预测性能,为处理复杂数据集上的回归问题提供了有效的解决方案,通过MapReduce的并行计算优势,可以在庞大的数据集上高效构建决策树回归模型,不仅提高了数据处理效率,也保证了模型的准确度和可靠性。
相关问答FAQs
Q1: MapReduce在决策树回归中的主要作用是什么?
A1: MapReduce在决策树回归中的主要作用是处理和准备大规模数据集,使其能够适用于决策树算法,它通过在Map阶段进行数据清洗、特征提取,并在Reduce阶段聚合数据,来加速决策树模型的训练过程。
Q2: 如何避免决策树回归中的过拟合问题?
A2: 避免决策树回归中的过拟合问题,可以通过剪枝(pruning)策略来实现,如预剪枝(prepruning)和后剪枝(postpruning),还可以使用正则化方法或者设置最小叶子节点大小等参数调整,以减少模型复杂度。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/907260.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复