

MapReduce模型简介
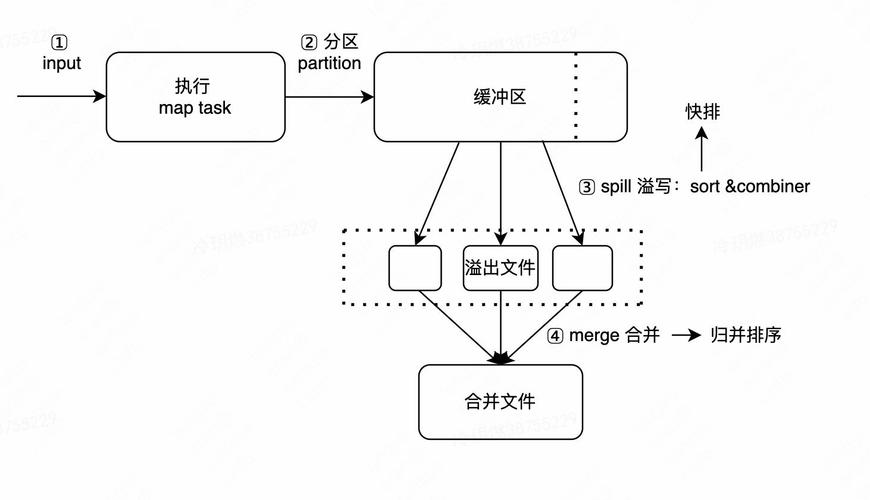

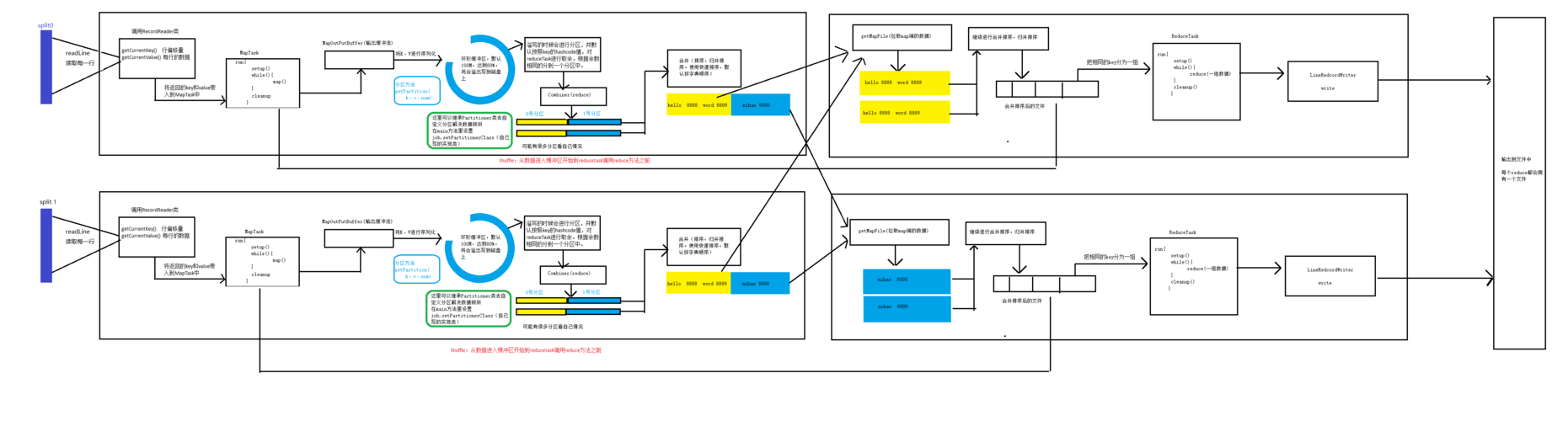
MapReduce编程模型是处理大规模数据集的计算范式,其核心在于两个基本操作:Map和Reduce,Map操作接受输入数据,并将其分解成一系列的键值对,而Reduce操作则负责处理由Map阶段产生的具有相同键的值,输出零个或多个键值对,下面将通过一个详细的编程实例来进一步阐述这一模型的步骤。
实例:词频统计任务
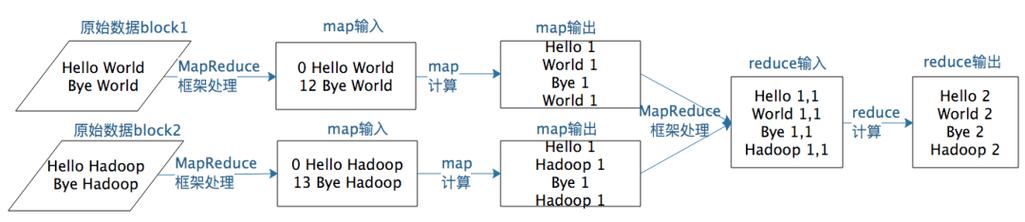
考虑一个实际的编程实例,如词频统计,假设我们有一个大型文本文件,需要统计其中每个单词出现的次数,按照MapReduce模型,我们将这个过程分为Map和Reduce两个阶段。
1、Map阶段
在Map阶段,程序会读取文本文件,为每个单词生成一个键值对,其中键是单词本身,值是该单词出现的次数(初始为1),如果文本中包含“apple”一词,Map函数会输出<"apple", 1>。
2、Shuffle阶段
在Shuffle阶段,系统会自动将所有Map输出的键值对按键进行排序和分组,这样,所有相同的键(即同一个单词)都会被归并到一起,形成一个<Key, Value集合>。
3、Reduce阶段
在Reduce阶段,每个唯一的键(单词)及其对应的值列表(出现次数的列表)会被传递给Reduce函数,Reduce函数将对所有值进行汇总,输出每个单词的总出现次数,如果“apple”出现了5次,Reduce函数会输出<"apple", 5>。
通过上述实例可以看出,MapReduce模型通过将复杂的数据处理任务分解为简单的Map和Reduce操作,极大地简化了并行计算的编程复杂性,这种模型不仅适用于词频统计,还可以广泛应用于其他各种需要大规模数据处理的场景。
相关问答FAQs
Q1: MapReduce模型中,Shuffle阶段是必要的吗?
A1: 是的,Shuffle阶段在MapReduce模型中是必要的,因为它负责将Map阶段的输出结果按键排序和分组,确保Reduce阶段能正确地对相同键的值进行处理。
Q2: 如何选择合适的MapReduce应用案例来进行学习?
A2: 选择具有明确输入输出、且数据处理逻辑可以清晰分解为Map和Reduce操作的案例最为合适,例如词频统计、计算平均成绩等,都是很好的入门级案例。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/907160.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复