

在Hadoop的MapReduce编程模型中,合理配置和调整作业(Job)优先级是优化集群资源利用、确保关键任务高效运行的重要手段,本文将深入探讨如何配置MapReduce Job的优先级,并解析相关设置对作业执行的影响,以帮助用户更有效地管理其大数据处理任务。
MapReduce Job优先级的概念:
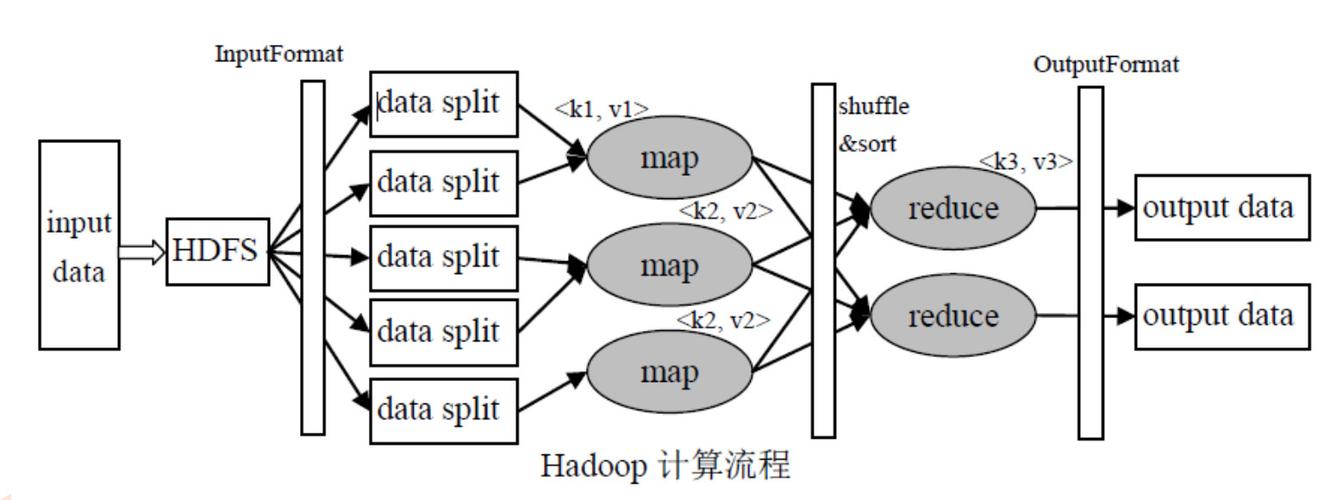
MapReduce是一个高效的大规模数据处理模型,适用于海量数据集的处理,在这种模型中,作业是由多个Map和Reduce任务组成的独立处理单元,每个作业会被提交到Hadoop集群,并由ResourceManager进行统一调度和管理,在多作业环境中,正确地设置作业优先级对于保证关键任务优先获得资源至关重要。
配置MapReduce Job优先级的方法:
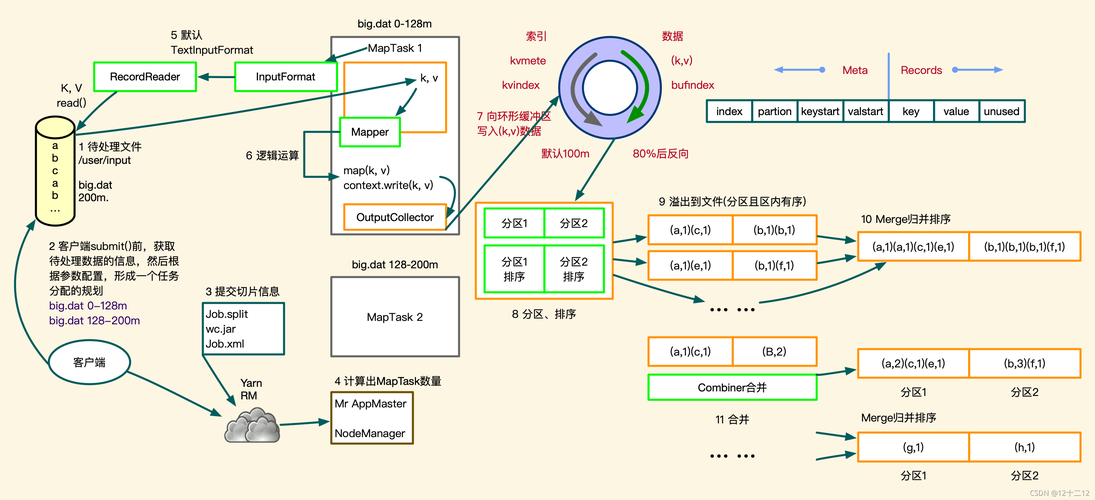
1. API方法:
通过编程方式直接在代码中设置作业优先级是最直观的配置方法之一,使用JobConf.setJobPriority()方法可以在Java程序中明确指定作业的优先级,设置作业为高优先级可以这样实现:
JobConf conf = new JobConf(); conf.setJobPriority(JobPriority.HIGH);
2. 配置文件方法:
另一种方法是在Hadoop的配置文件中设置mapreduce.job.priority属性,这需要在提交作业时通过D参数指定,如:
hadoop jar share/hadoop/mapreduce/hadoopmapreduceexamples2.8.5.jar wordcount D mapreduce.job.priority=30 /input /output
此命令将作业的优先级设置为30,这是一个中等优先级。
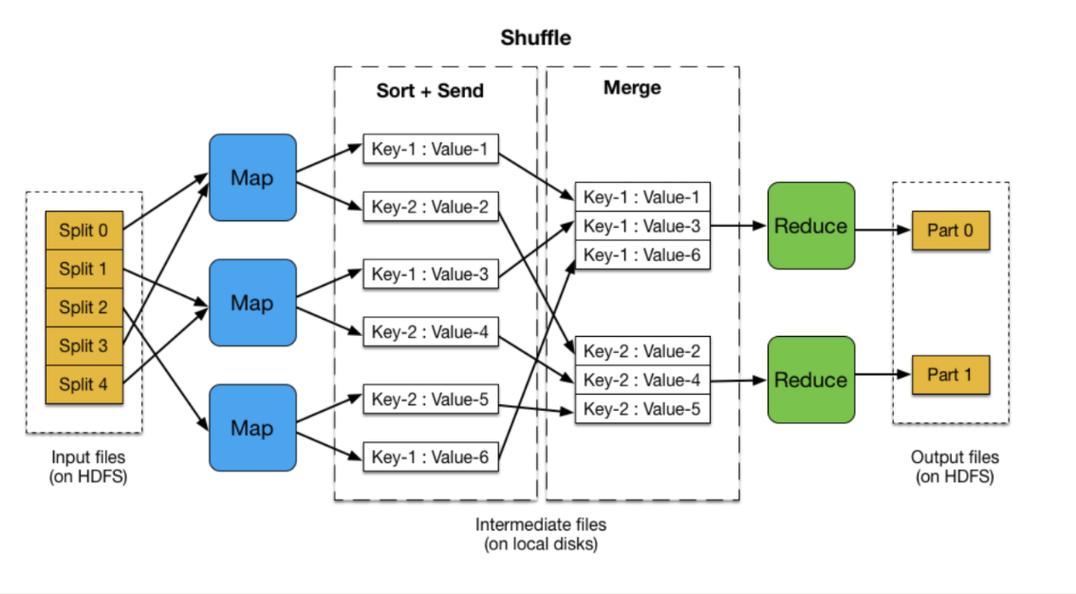
优先级的影响与调度:
作业的优先级影响其在集群中的资源分配,优先级高的作业能够更快地获取到计算资源(slot),从而加速执行过程,值得注意的是,不同优先级的作业在资源竞争时的表现差异明显,如果一个高优先级的作业和一个低优先级的作业同时运行,高优先级作业会获得更多的计算资源,从而更快完成。
集群管理员的角色:
在生产环境中,集群管理员通常已经根据作业的重要性对作业进行了分级,这意味着,并非所有用户都有权限随意更改自己作业的优先级,这种管理策略有助于避免资源滥用和确保关键业务逻辑的顺畅运行。
实践中的应用:
在实际应用中,企业和开发者需要根据业务需求和数据重要性合理安排作业优先级,对于实时性要求高的分析任务,应设置较高的优先级;而对于可以延时处理的后台任务,则可以设置为较低的优先级。
归纳意见:
理解和正确配置MapReduce作业优先级是提高Hadoop集群效率和响应速度的关键,通过合理的优先级设置,可以确保重要任务得到及时处理,同时也最大化资源的使用效率,不过,需要注意的是,优先级设置应结合企业的具体需求和策略进行,避免资源分配不公和系统过载。
相关问答FAQs
1. 如何查看当前作业的优先级?
可以在作业运行时通过ResourceManager的Web界面查看各个作业的优先级,或者在作业配置中查看mapreduce.job.priority属性的值。
2. 是否可以动态修改运行中作业的优先级?
不可以,作业的优先级在提交时被设定,一旦作业开始运行,其优先级就不可更改,动态调整优先级需要停止当前作业再重新提交,这样操作需谨慎以避免数据丢失。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/907009.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复