


MapReduce是Hadoop框架中的一个核心组件,用于处理大规模数据集,它通过分布式计算模型把作业分配到多个节点上并行处理,以此达到快速处理大量数据的目的,MapReduce的编程模型主要包括两个阶段:Map阶段和Reduce阶段,而在Map阶段的键(Key)则扮演着十分重要的角色,本文将深入探讨MapReduce中Map的Key的概念及其重要性,并详细解释MapReduce的工作机制。
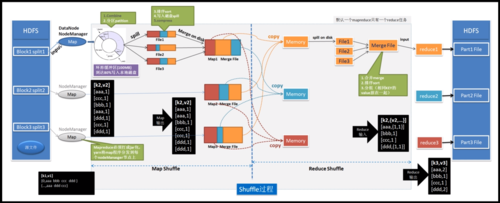

MapReduce的核心思想是“分而治之”,意在将大任务分解为小任务,并分发到不同的节点上并行处理,以提高处理效率和计算速度,在Map阶段,输入数据集被分解成一系列的键值对,这些键值对会传递给不同的Mapper函数进行处理,在此过程中,Map的Key起着至关重要的作用,因为它标识了每个键值对中的数据项,确保了数据的准确分类和后续处理的正确性。
Map的Key在数据处理中的具体作用可以分为几个方面,首先是数据标识的作用,Map的Key作为数据的标识符,使得系统能够正确区分和识别各个数据项,Map的Key还参与到数据的排序和分组中,在MapReduce的Shuffle阶段,中间键值对会根据Key进行排序和分组,这是为了将具有相同Key的值集合到一起,便于后续的Reduce处理,合理的Key设计还能优化数据的分区操作,提高数据处理的局部性和效率。
进一步地,MapReduce的整个工作流程可以细分为若干步骤,具体包括:
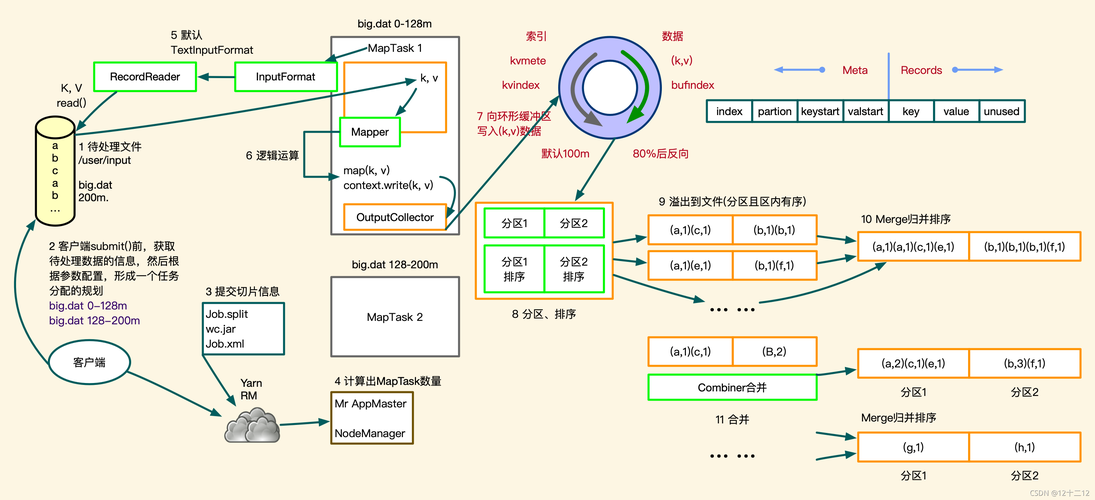
1、数据分片:输入数据集被划分为大小合适的数据块,并由不同的Mapper处理。
2、映射函数应用:Mapper对数据块中的每个元素应用用户定义的映射函数,此函数将每个输入元素转换为零个或多个中间键值对。
3、中间键值对生成:映射函数输出形成一系列中间键值对,其中键用于标识数据,值用于保存与键相关联的信息。
4、Shuffle和Sort:中间键值对通过Shuffle过程进行排序和分组,为下一阶段做准备。

5、Reduce阶段:具有相同Key的值被汇集到一起,然后由Reduce函数进行处理以产生最终结果。
MapReduce的Map阶段中的Key不仅是数据标识和处理的关键,也是实现高效数据处理和优化的重要考虑因素,正确地理解和使用Map的Key对于设计和优化MapReduce作业至关重要。
除此之外,关于MapReduce及Map的Key的理解和应用,还可以从以下几个方面进行拓展:
数据局部性优化:合理选择Key的划分策略,可以最小化网络传输开销,提高数据处理速度。
负载均衡:考虑到不同节点的处理能力,合理设计Key的分布可以避免某些节点成为瓶颈,影响整体性能。
容错机制:在设计Key的策略时考虑到容错机制,确保在节点故障的情况下,数据处理仍能正常进行。
相关问答FAQs:
Q1: MapReduce中的Map阶段能否处理非结构化数据?
A1: 是的,MapReduce能够处理非结构化数据,在Map阶段,用户可以自定义映射函数来处理各种格式的数据,包括文本、图像和其他类型的非结构化数据,关键在于设计适当的解析方法将非结构化数据转化为可以处理的键值对形式。
Q2: 如何选择合适的Map的Key以避免数据倾斜问题?
A2: 数据倾斜是指某些Key对应的数据量远大于其他Key,导致处理时间延长,避免数据倾斜的方法包括:预先分析数据的分布,选择能均匀分布数据的Key;使用组合Key或引入随机化因素打散热点Key;以及采用范围分区等高级分区策略,这些措施有助于实现数据在各个节点上的均匀分布,从而提高整体的处理效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/905124.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复