


树节点(TreeNode)

简介
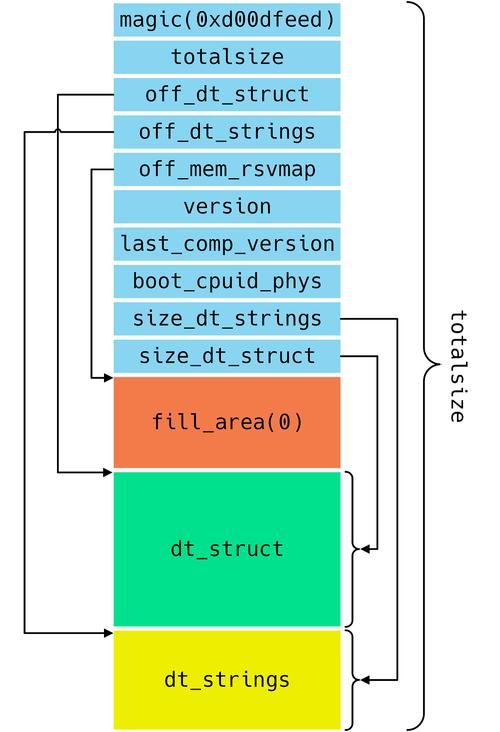
在计算机科学中,树是一种非线性数据结构,由节点和边组成,树节点(TreeNode)是构成树的基本单元,每个节点包含数据项以及指向其子节点的引用,树通常有一个特殊的节点称为根节点,它没有父节点,而其他节点则分为内部节点和叶子节点,内部节点有至少一个子节点,而叶子节点没有子节点。
树节点的结构
一个典型的树节点可能包含以下部分:
数据域:存储节点的值或信息。
链接域:存储指向子节点的引用集合。
在编程实现中,一个简单的树节点可以表示为:

class TreeNode:
def __init__(self, value):
self.value = value
self.children = [] 树的种类
根据树的性质不同,可以分为多种类型,
二叉树:每个节点最多有两个子节点。
多叉树(m叉树):每个节点可以有多个子节点。
平衡树:自动保持某种平衡条件以优化查找效率的树,如AVL树、红黑树等。
B树/B+树:主要用于数据库和文件系统的索引结构。
堆:一种特殊的完全二叉树,常用于实现优先队列。
树的遍历
树的遍历是指按照一定的规则访问树中的每个节点,并且每个节点只被访问一次,常见的树遍历算法包括:
深度优先遍历(DFS):先深入到可能的最远分支,再回溯至上一级节点继续遍历。
广度优先遍历(BFS):按层次从上到下,从左到右遍历树的节点。
深度优先遍历
前序遍历(Preorder):访问根节点→遍历左子树→遍历右子树。
中序遍历(Inorder):遍历左子树→访问根节点→遍历右子树。
后序遍历(Postorder):遍历左子树→遍历右子树→访问根节点。
广度优先遍历
层级遍历(Level Order):按层次顺序逐层遍历。
树的应用
解析表达式:将算术表达式表示为树结构,然后进行求值。
决策树:在机器学习中用来进行决策分析的预测模型。
文件系统:文件和目录的组织形式通常类似于树结构。
UI组件:一些用户界面库使用树来描述UI组件的层次结构。
实现细节
在具体实现时,需要考虑如下方面:
内存管理:动态分配和回收节点空间。
接口设计:提供方便的方法进行节点的插入、删除和查找。
迭代器模式:实现迭代器以便对树进行遍历操作。
性能考量
时间复杂度:不同的操作(如插入、删除和查找)具有不同的时间复杂度。
空间复杂度:树结构占用的内存大小,与节点数量有关。
平衡性:对于自平衡树来说,维护平衡状态是关键,会影响性能。
相关算法
路径压缩:在并查集中,用于减少树的高度,提高效率。
按秩合并:也是并查集优化技巧之一,用于减少树的深度。
常见问题解答(FAQs)
Q1: 什么是平衡二叉树?
A1: 平衡二叉树是一种特殊的二叉树,它会在任何时候确保树的高度尽可能小,通常是通过旋转操作来重新平衡树的结构,这样做的目的是保证树的操作(如插入、删除和查找)的时间复杂度接近O(log n),其中n是树中节点的数量,常见的平衡二叉树有AVL树和红黑树。
Q2: 如何判断一个树是否是平衡的?
A2: 判断一个二叉树是否平衡,可以通过检查它的任意两个叶子节点的深度是否相差不超过一定值(通常为1或2,取决于树的类型),一种方法是通过递归函数来计算左右子树的高度,如果两者高度差超过允许的范围,则树不平衡;否则,继续递归检查子树,还可以通过中序遍历输出节点并根据输出结果判断树是否平衡。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/904234.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复