


MapReduce是一种编程模型,用于处理和生成大数据集,该技术在分布式计算环境中尤为流行,因为它可以将任务分发到多个计算节点上并行处理,从而加快数据处理速度,本文将深入探讨MapReduce的核心概念、架构设计、编程实践及其应用场景,帮助读者全面理解并有效运用MapReduce处理大数据问题。

MapReduce基础理论
1.1 初始MapReduce
理解MapReduce思想:MapReduce核心思想是将复杂的数据处理任务分解为“映射”(Map)和“归约”(Reduce)两个阶段,在映射阶段,系统将数据拆分成小块,分配给不同的节点并行处理;归约阶段则将处理后的结果汇总,输出最终结果。
如何模拟实现分布式计算:通过模拟,可以在单机环境下理解分布式计算的基本流程,即数据分割、任务分配、结果汇总和输出。
分布式计算和并行计算的区别与联系:分布式计算强调在多台计算机上协同处理任务,而并行计算强调在同一台计算机上通过多线程或多进程同时处理任务,两者在MapReduce中都有所体现。
分布式并行编程:在MapReduce框架下,开发者需要编写能够在分布式环境中并行执行的代码,这要求对数据的分区、任务的分配及异常处理有充分的考虑。
1.2 Hadoop MapReduce简介
MapReduce介绍:作为Hadoop生态系统的一部分,Hadoop MapReduce提供了一个易于使用的高性能平台,用于大规模数据集的处理。
MapReduce优缺点:优点包括高扩展性、高容错性和适用于多种数据处理场景,缺点是编程模型相对僵硬,不适用于所有类型的数据处理需求,如实时数据处理。
Hadoop MapReduce编程
1.3 编程实践
Hadoop MapReduce编程:开发者需要了解MapReduce程序的基本结构,包括Mapper、Reducer的编写,以及如何配置作业运行参数。
Hadoop中的数据类型:理解Hadoop支持的数据类型及其使用场景,有助于更高效地处理数据。
Hadoop的序列化机制:掌握Hadoop中的序列化机制对于优化数据传输和存储至关重要。
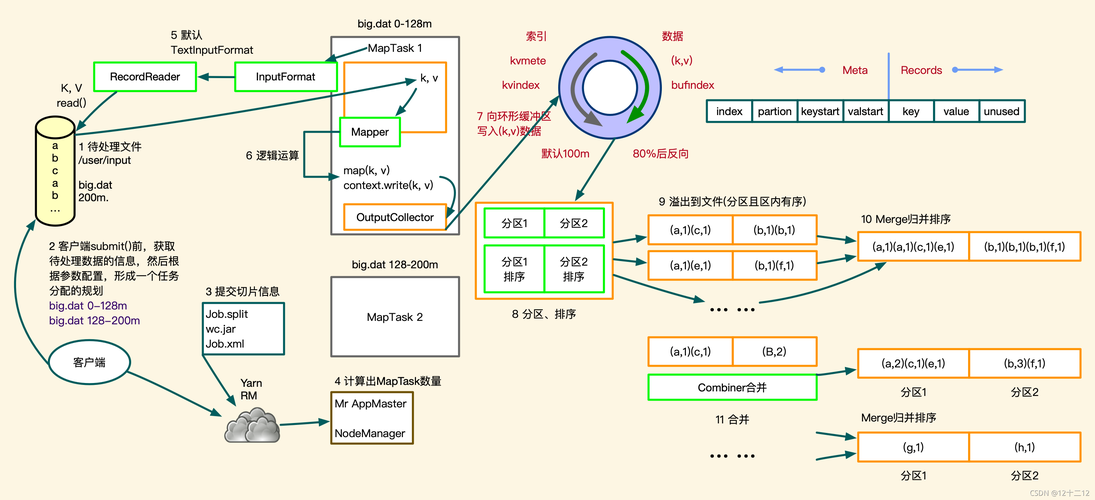
序列化(排序案例实操):通过具体的排序案例,深入理解序列化在MapReduce中的作用与实现。
1.4 经典案例分析
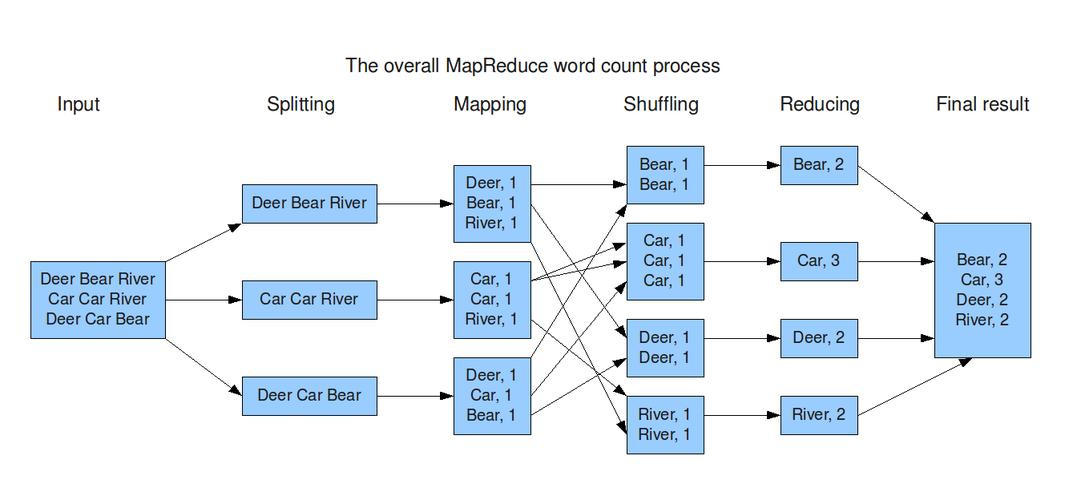
WordCount程序任务:作为MapReduce的经典入门案例,WordCount展示了如何统计文本数据中各单词的出现次数,通过分析其代码实现,可以加深对MapReduce编程模型的理解。
工作原理与组件详解
2.1 工作原理
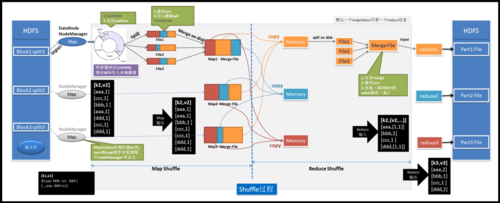
输入文件至OutputFormat:MapReduce作业执行过程中,数据从输入文件开始,经过InputFormat、InputSplit、RecordReader分块读取,Mapper处理,Combiner优化,Partitioner分区,Shuffle混洗,最终由Reducer处理并由RecordWriter、OutputFormat输出结果。
2.2 核心组件
Mapper: 负责处理输入数据并生成中间键值对。
Reducer: 负责接收具有相同键的键值对,并进行汇总处理。
Partitioner: 决定中间键值对发送到哪个Reducer。
Shuffle: 是连接Mapper和Reducer的过程,涉及数据传输和混合。
相关资源与服务
3.1 资源获取
MapReduce Service云计算:提供了配置手册、文档、软件下载等资源,方便用户学习和使用MapReduce。
3.2 教程与文档
MapReduce教程:涵盖了基本概念、编程模型、案例分析和优化技巧,适合不同层次的读者。
FAQs
为什么MapReduce在处理大数据时如此强大?
因为其分布式和并行处理的能力,MapReduce可以将一个大任务分解为多个小任务,并行处理,显著提高了数据处理速度,其容错机制确保了在硬件故障情况下任务仍可正常完成。
MapReduce编程有哪些挑战?
主要挑战包括任务划分、数据倾斜处理和性能优化,合理划分任务和处理数据倾斜是保证MapReduce效率的关键,性能优化则需要对Hadoop生态系统有深入的了解和实践经验。
MapReduce作为一个强大的分布式数据处理框架,通过其独特的编程模型和架构设计,有效地解决了大规模数据处理的挑战,无论是初学者还是有经验的开发者,掌握MapReduce的基础理论、编程实践和优化技巧都是处理大数据问题的重要步骤,通过深入学习和实践,可以更好地利用MapReduce解决实际问题,发掘大数据的价值。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/904210.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复