


MapReduce和MPI(Message Passing Interface),比较它们在通信机制、容错性和编程模型等方面的差异,并分析各自适用的场景,具体内容如下:

1、通信机制
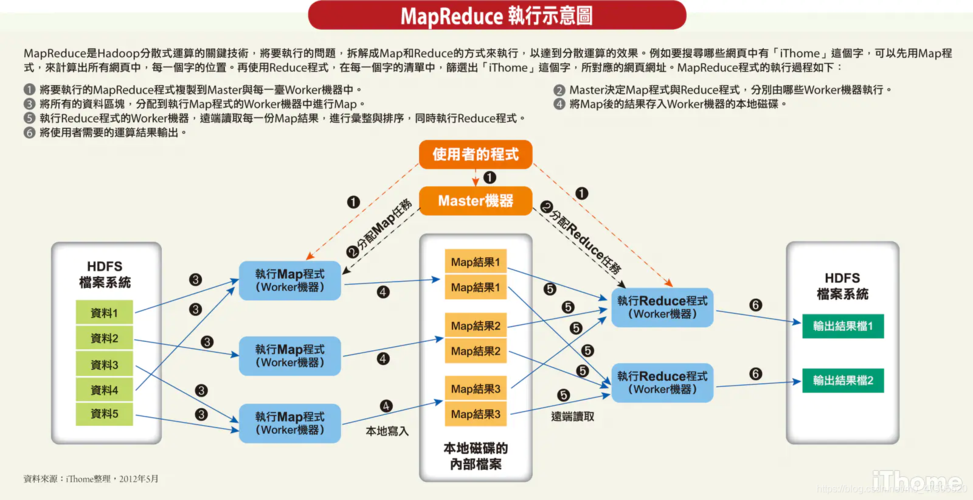
MapReduce:采用了自动的数据分片和任务分配机制,它通过一个主节点来协调各个工作节点的任务执行,数据的传输和通信管理由框架自身处理。
MPI:作为一个标准的消息传递接口,MPI允许程序在分布式环境中通过发送和接收消息进行通信,它提供了更细粒度的控制,但需要开发者自行管理数据交换和同步过程。
2、容错性
MapReduce:设计了内置的容错机制,可以自动处理节点失败的问题,如果某个任务执行失败,主节点可以调度其他节点重新执行该任务。
MPI:依赖于开发者来处理节点间的故障恢复,在MPI中,错误处理和故障恢复通常需要手动实现,这增加了编程的复杂性。
3、编程模型
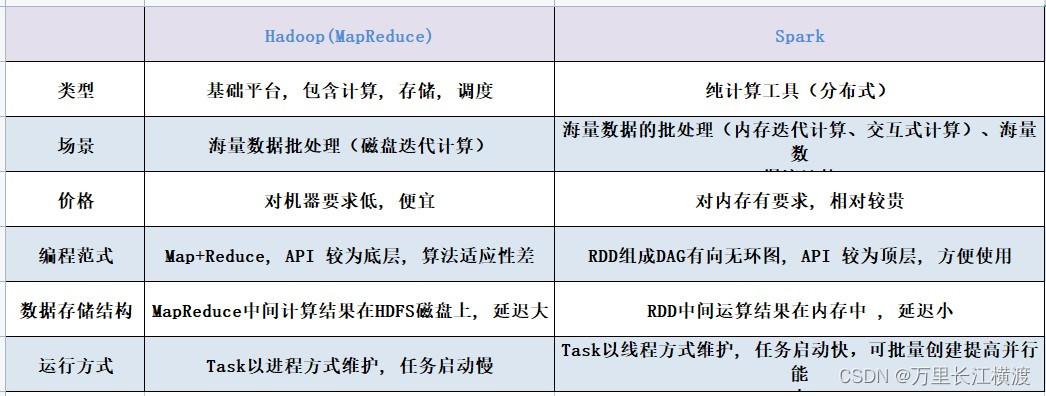
MapReduce:用户只需实现Map和Reduce两个函数,即可实现并行处理逻辑,这种简化的编程模型使得非专业人员也能较容易地编写并行应用。
MPI:提供了一个低层次的消息传递模型,开发者需要显式地处理数据分布、进程间通信和同步,这要求开发者具有更高的并行编程技能。
4、数据处理方式
MapReduce:适用于数据密集型的分布式处理,不涉及实时计算,它通过分而治之的方法处理大规模数据集,中间结果需要存储到分布式文件系统中。
MPI:适合计算密集型任务,尤其是在科学研究和工程模拟中的高性能计算,因为MPI作业通常在内存中执行,不需要频繁的磁盘I/O操作。
5、可扩展性
MapReduce:设计用于易于扩展到大量节点的集群,如Google和Hadoop集群,这种设计使得MapReduce非常适合商业云环境和大数据应用。

MPI:虽然MPI也支持大规模并行环境,但相比之下,其编程和维护的复杂度在超大规模集群中可能会成为一个挑战。
针对上述分析,提出以下几点建议:
对于需要处理大规模数据集并且希望快速实施的应用,推荐使用MapReduce。
对于计算密集型任务,特别是在科学计算领域,可以考虑使用MPI。
MapReduce为处理大规模数据提供了一种高效的编程模型,尤其适合于数据密集型的云计算环境,而MPI则提供了强大的灵活性和控制力,适合于那些需要精细调整的计算密集型应用,在选择适合的模型时,应综合考虑实际应用的需求、开发成本及性能指标。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/903838.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复