


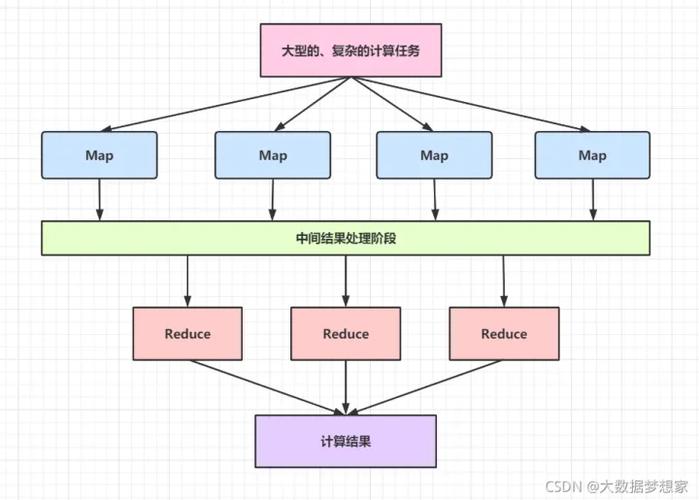
MapReduce是一种强大的分布式计算框架,专用于处理大规模数据集,这种模型的核心在于将复杂的数据处理任务分解为两个基本阶段:Map和Reduce,通过这种方式可以显著提高处理大规模数据的效率。


Map阶段
在Map阶段,系统将大规模数据集分成多个小块,每个块分别由不同的计算节点(或处理器)处理,每个节点对其分配的数据块执行用户定义的map()函数,这个函数负责将输入数据转换为一组键值对,简单地说,Map阶段的任务就是将数据进行分类和过滤,准备下一步的合并操作。
Reduce阶段
在Map阶段的输出被排序和分类后,Reduce阶段开始执行,这个阶段中,系统会将具有相同键的所有值聚集到一起,并传递给用户定义的reduce()函数,Reduce函数则负责处理这些值,并输出最终结果,Reduce阶段用于数据的汇总或聚合操作,如计数、求和等。
MapReduce的优势
易于编程:用户只需实现map()和reduce()两个函数即可完成复杂的数据处理任务。
扩展性强:能够轻松扩展至大量的计算节点,有效支持数据量的快速增长。
容错性高:单点故障不影响整体任务的完成,系统可自动处理失败节点的任务重分配。
MapReduce的应用实例
MapReduce广泛应用于各种需要处理大量数据的领域,如日志分析、数据挖掘、机器学习等,一个常见的应用是大型网站的日志文件分析,Map函数可以用来统计每个页面的访问次数,而Reduce函数则用来对访问次数进行汇总,从而得到网站的整体访问分析报告。
实施技术与工具
Hadoop:是一个开源框架,支持使用简单的编程模型来处理跨计算机集群的大规模数据集,Hadoop中的HDFS提供高吞吐量的数据访问,非常适合带有大数据量的应用。
Apache Spark:相较于Hadoop, Spark提供了更高效的内存计算能力,可以在更短的时间内处理数据分析任务。
相关FAQs
1. MapReduce适用于哪些场景?
MapReduce特别适合于处理大量非结构化或半结构化数据的场景,常见的应用场景包括大数据分析、日志处理、文本挖掘等。
2. MapReduce有哪些局限性?
尽管MapReduce非常强大,但它也存在一些局限,对于需要实时响应的数据处理任务,由于MapReduce设计上是为批处理优化的,因此可能不是最佳选择,对于相互之间有强依赖的复杂数据处理流程,使用MapReduce也可能导致效率低下。
MapReduce作为一种高效的分布式计算框架,通过简化编程模型,使得处理大规模数据集变得可行且高效,其分而治之的思想极大地推动了大数据技术的发展和应用,使其在各个领域都得到了广泛的应用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/903626.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复