


在当今大数据时代,MapReduce和HBase作为处理大规模数据集的关键技术,其重要性不言而喻,本文旨在通过实战案例,深入探讨如何高效地结合使用MapReduce与HBase,以应对复杂的数据处理需求。


MapReduce优化策略
1、Map阶段优化
输入数据拆分:Map阶段的核心在于将大数据集分割成小块,以便并行处理,优化数据拆分可以大幅提高处理速度,合理设置输入切片大小(input split size),可以确保每个Map任务处理适量的数据,避免个别任务执行时间过长而影响整体效率。
.内存管理:优化Map任务的内存使用是提高性能的关键,通过调整JVM的堆设置或使用压缩技术减少数据传输量,可以有效减少内存消耗,加快处理速度。
2、Reduce阶段优化
数据聚合:在Reduce之前使用Combiner和Inmapper combining可以显著减少数据通过网络传输的量,这是因为这些技术可以在Map端就进行局部汇总,从而减少数据在网络中的传输量及Reduce阶段的负载。
.并行处理:合理设置Reduce任务的数量也非常关键,过多的Reduce任务会导致资源争用,而过少则会造成某些节点负载过高,根据CPU和IO资源的实际情况调整Reduce任务数量,以达到最佳负载均衡。
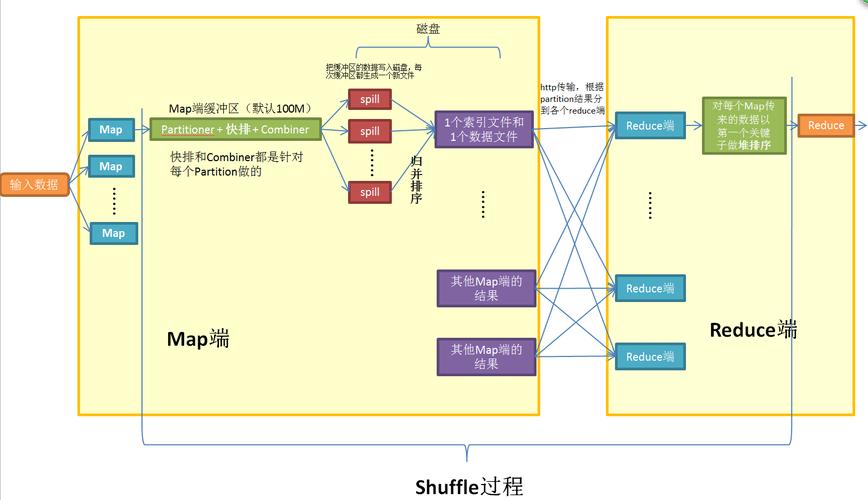
3、数据格式与存储优化
序列化框架选择:使用高效的序列化框架(如Avro、Parquet等)可以优化数据的存储和读取速度,这些格式不仅减小了存储空间,还提高了数据处理效率。
.存储策略优化:对于频繁访问的数据,可以采用缓存机制或分布式缓存技术,减少数据读取时间,提高响应速度。
4、容错与监控
错误恢复:MapReduce框架本身具有较好的容错性,但进一步优化错误恢复过程,如调整重试策略和失败节点的快速检测,可以最小化故障对作业的影响。
监控与诊断:实施全面监控系统,包括硬件资源使用情况、任务运行状态等,可以帮助管理员及时发现并解决问题。
HBase与MapReduce集成
1、环境准备与配置
集群部署:构建包含HBase组件的EMR(Elastic MapReduce)集群,为运行MapReduce程序提供基础设施。
前提条件:需要有Linux运维基础、理解Hadoop基本组件以及HBase的基本操作知识。
2、实现数据操作
数据模型理解:HBase的数据模型包括命名空间、表、行键、列族等,了解这些基础知识是进行高级操作的前提。
数据迁移流程:通过编写特定的MapReduce程序实现对HBase数据的批量导入导出,这对于大规模数据集的处理尤为重要。
3、实战案例分析
统计分析实现:计算HBase中某列的平均值,这不仅涉及数据的读取,还包括在Reduce阶段进行复杂的聚合操作。
扩展应用场景:除了基本的数据统计,可以扩展到更复杂的数据分析任务,如大数据量的实时分析和多维度的数据聚合。
FAQs
Q1: 如何选择合适的序列化框架?
Q2: 在高并发场景下,如何保证HBase的性能?
MapReduce和HBase的结合提供了强大的数据处理能力,通过优化MapReduce作业的配置和执行策略,以及合理地利用HBase的存储与查询优势,可以有效地解决大规模数据处理问题,实际操作中需要注意细节的调整和系统的监控,以保证数据处理流程的平稳高效运行。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/903141.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复