


拉丁1编码(latin1)


拉丁1编码,全称ISO 88591,是一种8位的字符编码标准,用于表示西欧语言,它是由国际标准化组织(ISO)在1987年制定的,旨在提供一种覆盖欧洲使用的所有字母、音标和符号的编码方案,由于其设计简单且兼容性较好,拉丁1编码在早期互联网和计算机系统中得到了广泛应用。
编码范围与特点
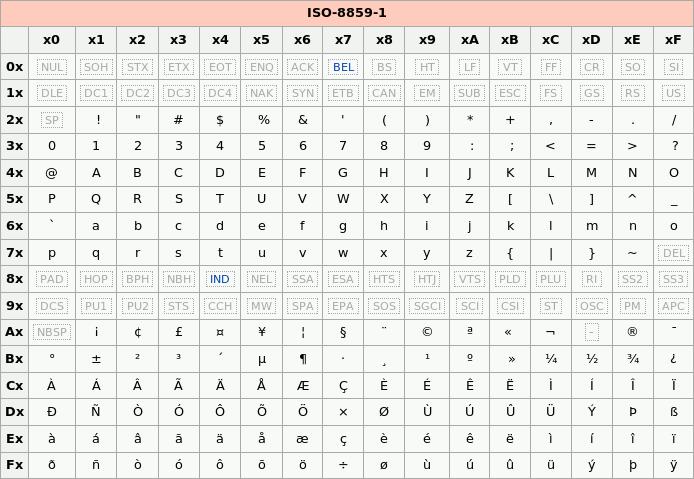
拉丁1编码涵盖了从十六进制的00到FF的256个代码点,其中每个代码点对应一个特定的字符,该编码包含了:
大写和小写的拉丁字母A至Z
常用的音标和符号
一些控制字符
拉丁1编码的特点是它能够支持多种西欧语言,包括英语、法语、德语、西班牙语等,但不包括东欧、亚洲或非洲的语言。
与其他编码的关系
拉丁1编码是ISO 8859系列中的第一个成员,随后发展出多个变体以支持其他语言和符号集,比如ISO 88592(拉丁2)用于东欧语言,ISO 88593(拉丁3)用于土耳其语等,Unicode作为一种更全面的字符编码标准,旨在包含世界上所有文字系统的字符,也与拉丁1编码存在兼容性问题。
应用场景
拉丁1编码因其简洁性,在早期的软件和硬件设备中得到应用,尤其是在那些只需要处理西欧语言的场景中,随着全球化和多语言环境的需求增加,更全面的编码系统如Unicode逐渐取代了拉丁1编码的地位。
优缺点分析
优点
1、简单易用:由于只有256个不同的字符,实现起来相对简单。

2、兼容性良好:许多旧系统和文档默认采用拉丁1编码。
3、涵盖主要西欧语言:对于只涉及西欧语言的应用来说足够使用。
缺点
1、字符集有限:不支持东欧、亚洲、非洲等地区的语言。
2、扩展性不足:无法通过简单的扩展来支持更多语言。
3、与Unicode不兼容:在需要多语言支持的现代环境中,兼容性成问题。
未来趋势
随着信息技术的发展,对字符编码的要求越来越高,拉丁1编码由于其局限性正逐渐被淘汰,Unicode作为现代编码标准,已经成为主流,提供了更广泛的字符覆盖和更好的国际化支持,尽管如此,在某些特定领域和历史遗留系统中,拉丁1编码仍然有其存在的价值。
相关FAQs
Q1: 拉丁1编码是否还适用于现代网络环境?
A1: 拉丁1编码已经不适应现代网络环境的需求,由于它不能覆盖全球所有语言的文字,因此在多语言和国际化的应用场景下不再适用,现代网络环境更倾向于使用Unicode编码,因为它能提供更全面的语言支持和更好的兼容性。
Q2: 如果需要在现代系统中使用拉丁1编码的文档,应该如何处理?
A2: 如果需要在现代系统中使用拉丁1编码的文档,通常需要将文档转换为Unicode编码,这可以通过各种文本编辑器或专用的转换工具来完成,转换过程需要注意字符映射的正确性,确保转换后的文档保持原有的内容和格式。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/902165.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复