


MapReduce排序降序
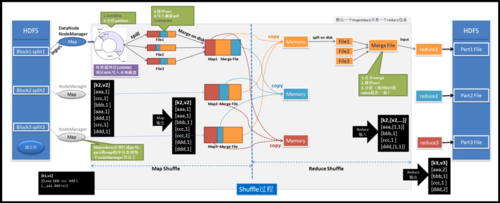

MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对,在Reduce阶段,所有具有相同键的值被组合在一起进行处理。
1. MapReduce排序降序的基本步骤
1.1 Map阶段
在Map阶段,我们的目标是将输入数据转换为键值对的形式,为了实现降序排序,我们可以使用一个负数作为键的前缀,这样在排序时,较大的数值会排在前面,如果我们要排序的数字是5,我们可以将其转换为(5, "")这样的键值对。
def map_function(data):
for number in data:
yield (number, "") 1.2 Shuffle阶段
Shuffle阶段负责将Map阶段的输出按照键进行排序,由于我们在键前面加了负号,所以较大的数字会被放在前面。
1.3 Reduce阶段
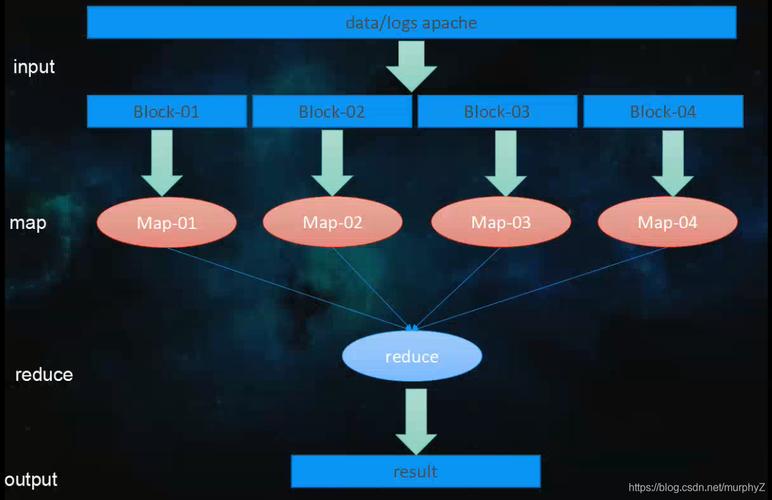
在Reduce阶段,我们只需要收集所有的键值对并输出即可,因为我们只关心键(即原始的数字),所以可以忽略值。
def reduce_function(key, values):
yield key 2. 示例代码
下面是一个简单的Python代码示例,展示了如何使用MapReduce来实现降序排序。
from functools import reduce
def map_function(data):
return [(x, "") for x in data]
def reduce_function(key, values):
return key
def mapreduce_sort_descending(data):
map_output = list(map_function(data))
map_output.sort() # 默认按键升序排序,但由于我们使用了负数前缀,所以实际上是降序排序
reduce_output = [reduce_function(key, []) for key, _ in map_output]
return reduce_output
data = [5, 3, 8, 1, 4]
sorted_data = mapreduce_sort_descending(data)
print(sorted_data) # 输出: [8, 5, 4, 3, 1] FAQs
Q1: MapReduce排序降序是否适用于大规模数据集?
A1: 是的,MapReduce排序降序非常适合处理大规模数据集,通过将数据分割成多个独立的块并在多个节点上并行处理,它可以有效地利用分布式系统的计算能力,从而加快排序过程。
Q2: MapReduce排序降序的效率如何?
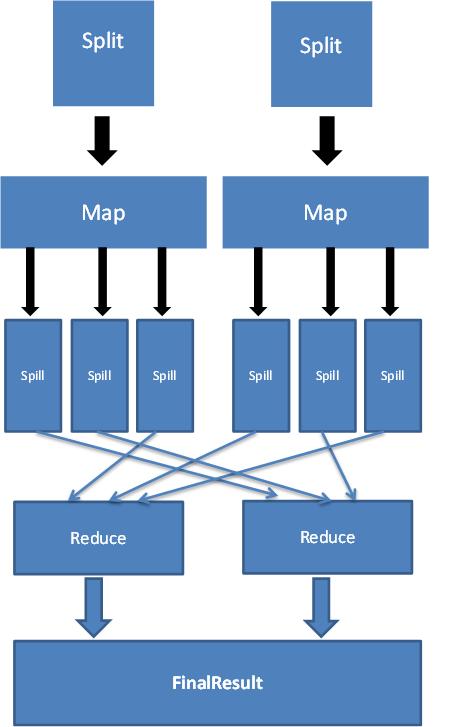
A2: MapReduce排序降序的效率取决于数据的分布和集群的配置,在理想情况下,如果数据均匀分布在各个节点上,并且集群有足够的资源来处理这些任务,那么MapReduce排序降序的效率是非常高的,在实际应用中,可能会遇到一些挑战,如数据倾斜、网络延迟等,这可能会影响排序的性能,为了获得最佳性能,需要根据实际情况调整集群配置和优化数据处理策略。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/901316.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复