


在大数据时代,Hadoop MapReduce框架是处理大规模数据集的关键技术之一,MapReduce作业的性能优化不仅能够提高数据处理速度,还能有效节约计算资源,进而降低成本,参数调优作为性能优化的重要环节,涉及到诸多细节和技巧,下面将详细解析MapReduce参数调优的关键方面,并给出实用的调优建议:
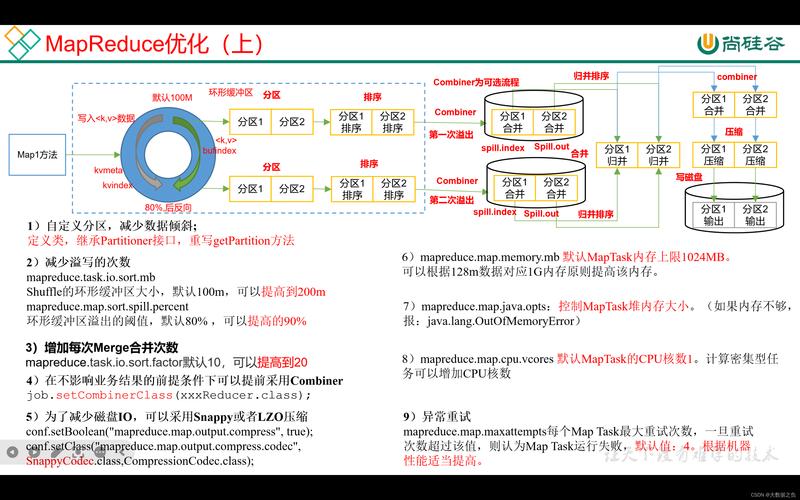

1、资源相关参数调整
内存优化:对于Mapper和Reducer的内存配置,合理设置mapreduce.map.memory.mb和mapreduce.reduce.memory.mb参数可以防止作业执行过程中的内存溢出问题,如果作业中Reducer的任务对内存需求不高,可以将mapreduce.reduce.merge.inmem.threshold设为0,同时将mapreduce.reduce.input.buffer.percent设为1.0,使更多数据保存在内存中,从而提升性能。
CPU优化:通过调整mapreduce.job.cpus参数,可以设定每个任务使用的虚拟CPU核心数,以匹配不同作业的计算需求。
2、Shuffle与Sort参数调整
高效Shuffle处理:Shuffle是MapReduce中数据从Map任务传输到Reduce任务的一个关键过程,优化Shuffle过程能显著提升作业性能,通过调整mapreduce.shuffle.max.threads以控制用于Shuffle操作的最大线程数,可以加快数据传输效率。
排序效率提升:Sort阶段的效率直接影响到Reduce任务的开始,合理设置mapreduce.task.io.sort.factor(决定环形缓冲区的大小)和mapreduce.reduce.input.buffer.percent(用于保存Map输出文件的堆内存比例)等参数,可以提升排序性能。
3、IO与磁盘相关参数调整
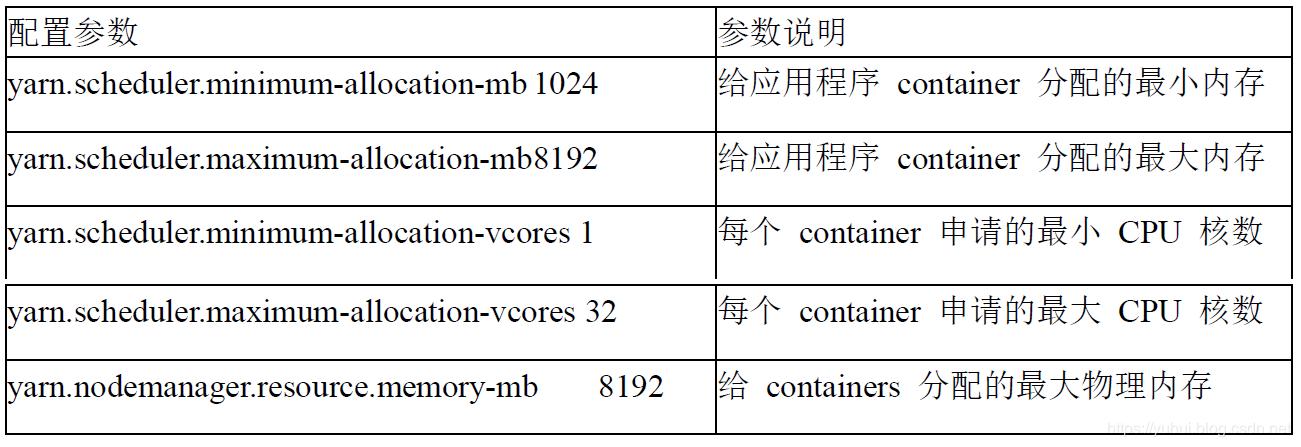
减少小文件处理问题:处理大量小文件是Hadoop的一个常见问题,因为这会导致频繁的寻址和元数据操作,降低效率,解决方案包括使用CombineTextInputFormat或启用Uber模式来合成小文件,从而减少Map任务的数量和提高处理速度。
系统级别优化:操作系统和硬件配置也会影响MapReduce作业的执行效率,优化磁盘I/O调度器、关闭操作系统的Swap功能,以及启用预读取机制等措施,都可以进一步加速数据处理过程。
4、网络参数调整
调整TCP窗口大小:在分布式环境中,网络带宽是限制因素之一,通过调整网络参数如TCP窗口大小,可以增加数据传输的吞吐量,减少网络延迟的影响。
MapReduce的参数调优是一个涉及多个层面的复杂过程,包括但不限于资源配置、Shuffle性能、IO与磁盘优化以及网络参数调整,每项调整都需针对实际作业的特点和集群环境进行精细的配置。
接下来是两个相关的FAQs,旨在进一步解答有关MapReduce参数调优的常见疑问:
FAQs

Q1: 如何确定MapReduce作业中的最优资源参数配置?
A1: 最优资源配置通常需要根据作业的具体需求和集群的实际能力来定,可以通过监控工具获取作业的资源使用情况(如CPU、内存和磁盘IO),然后根据监控数据调整mapredsite.xml和yarnsite.xml中的参数,若发现CPU使用率不高,可以适当减少mapreduce.job.cpus的配置值;若内存使用频繁超出阈值,应增加mapreduce.map.memory.mb或mapreduce.reduce.memory.mb的值。
Q2: 如何应对MapReduce作业中的Stragglers问题?
A2: Stragglers是指那些运行速度明显慢于其他并行任务的任务,应对Stragglers的策略包括:
增加冗余执行:配置yarn.app.mapreduce.am.job.recovery.enable为true,可以让失败的任务在另一个节点上重新启动。
优化输入数据:检查数据分布是否均匀,必要时采用数据预处理方法,如数据倾斜处理。
调整资源分配:根据任务的实际运行情况调整内存和CPU分配,确保所有任务都能获得足够的资源。
MapReduce参数调优是一个综合性的过程,需要考虑多方面因素,通过不断试验和调整,结合具体的业务场景和集群环境,可以逐步找到最合适的参数配置,从而实现作业性能的最优化。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/900724.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复