


在MapReduce编程模型中,compare_custom_op_compare函数是一个自定义比较函数,用于在处理大数据时对键(Key)进行排序,下面将深入探讨这个函数的作用、实现方式及其重要性:
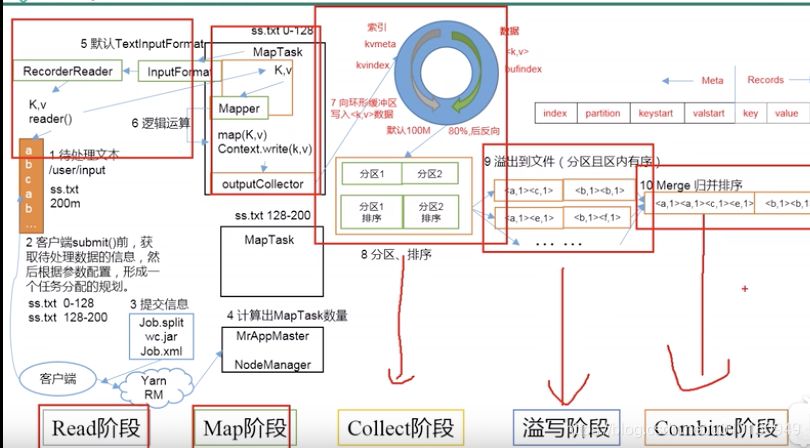

1、MapReduce模型基础
基本概念: MapReduce由Google提出,是一种处理大规模数据集的编程模型,分为Map和Reduce两个阶段,Map阶段对数据进行过滤和分类,而Reduce阶段则对数据进行汇总。
数据处理过程: 在Map阶段,输入数据被分成多个小块,每块分别处理并生成中间键值对;Reduce阶段则将所有具有相同键的值合并,以生成最终的输出结果。
2、自定义比较函数的需求
默认比较器的局限性: Hadoop MapReduce框架提供了多种内建的键类型,如Text、LongWritable等,但对于复杂的多维键,这些内建类型可能无法满足特定需求。
复杂数据类型的处理: 当键由多个字段组合而成或者需要进行特殊的排序逻辑时,就需要实现自定义的比较器来正确排序键,确保Reduce阶段的有效性和准确性。
3、实现自定义比较函数

继承WritableComparator: 自定义比较器通常通过继承Hadoop的WritableComparator类来实现,这样可以利用其提供的compare方法模板,根据实际需求重写此方法。
比较逻辑的实现: 在compare方法中,需要根据自定义的规则比较两个字节数组b1和b2的部分或全部长度,并确定它们的顺序。
4、应用情景与实例
处理复合键: 一个由多个字段组成的复合键可能需要按其中某个字段优先级更高的方式来排序,这可以通过自定义比较器实现。
特殊排序需求: 在某些情况下,数据需要按照非自然顺序(如倒序)来排序,自定义比较器可以灵活实现此类需求。
5、性能优化与考量
优化Sort阶段: 自定义比较器直接影响了MapReduce中的Sort阶段,正确的比较逻辑可以减少不必要的数据处理,提高整体性能。

资源利用: 合理的比较逻辑可以减少内存使用和CPU消耗,特别是在处理大量数据时,这种优化显得尤为重要。
为了全面理解compare_custom_op_compare函数的应用,下面列出了一些相关的常见问题及解答:
FAQs
Q1: 为什么需要使用自定义比较器?
A1: 使用自定义比较器是为了处理复杂的键排序需求,例如多字段键、自定义排序规则等,这在默认的Hadoop键类型中无法直接实现。
Q2: 自定义比较器如何影响MapReduce的性能?
A2: 自定义比较器能优化排序阶段,减少不必要的计算和内存使用,特别是对于大规模数据集,适当的优化可以显著提高MapReduce作业的整体性能。
compare_custom_op_compare函数在MapReduce编程模型中扮演着关键的角色,它允许开发者根据具体需求实现自定义的排序逻辑,解决复杂数据处理问题,通过有效地管理和优化这一环节,可以大幅提升大数据处理任务的效率和准确性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/900343.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复