


在当今大数据时代,存储效率和数据处理速度变得至关重要,Apache Parquet作为一种列式存储格式,被设计用于提高数据处理的效率,特别是在Hadoop生态圈及其他大数据框架中,Parquet支持多种压缩和解压缩技术,其中包括ZSTD(Zstandard)算法,这是一种高效的数据压缩算法,其性能和压缩比均优于其他现有压缩格式,下面将深入探讨MapReduce存储中使用Parquet格式以及Hive对ZSTD压缩格式的支持,并回答相关的常见问题。

背景与原理解析
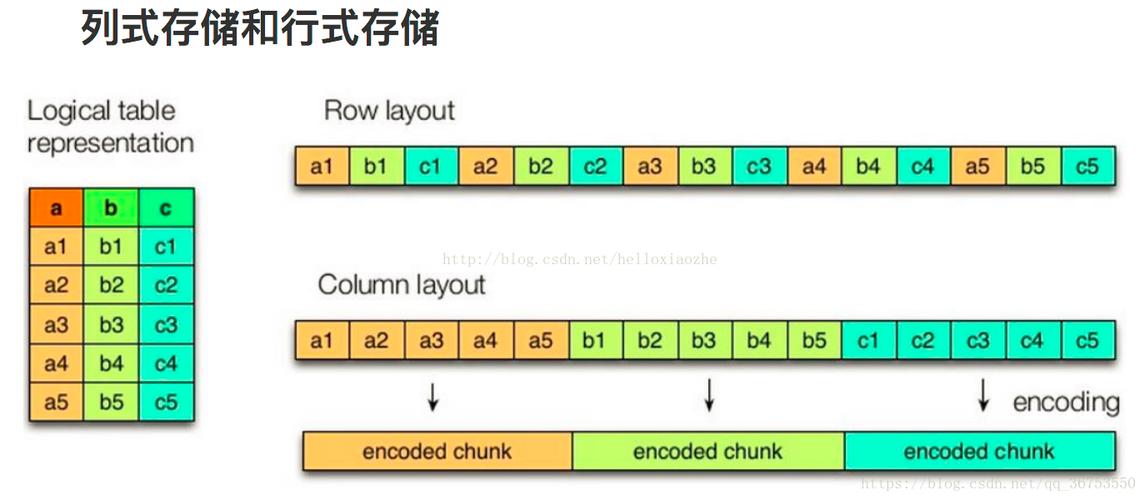
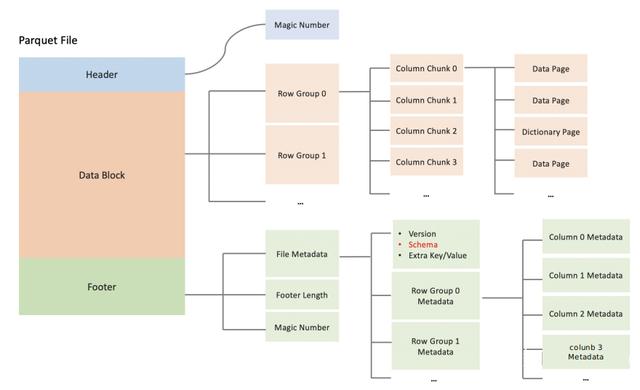
1、Parquet的存储机制:
Parquet专为列式存储设计,使得读取数据集中的特定列时无需解析整个行,从而提高I/O效率。
支持各种数据模型和查询引擎,如Apache Hive、Apache Spark等,使其成为大数据分析的理想选择。
通过Row Groups(RG)和Pages进一步细分数据,每个RG包含多个列的数据块,这有助于优化数据访问和编码效率。
2、MapReduce与Parquet的集成:
MapReduce是Hadoop生态中的一个计算框架,用于处理大规模数据集。
使用Parquet格式存储数据可以显著提升MapReduce作业的读写效率和整体性能。
3、ZSTD压缩算法的优势:
ZSTD提供高压缩比和快速的压缩解压速度,适合大数据场景。
在保持数据完整性的同时减少存储空间的需求,节约成本。
4、Hive对ZSTD的支持:
Hive可以通过简单的配置启用ZSTD压缩,适用于ORC、Parquet等多种文件格式。
使用ZSTD压缩的Hive表在查询性能上可以媲美或超过使用其他压缩算法的表。
5、实现与配置:
在Hive中启用ZSTD支持通常只需在Hive配置中设置合适的压缩代码c和相关属性。
对于Parquet,可以通过修改MapReduce作业的配置,使其在写入数据时使用ZSTD压缩。
优势分析
1、存储效率:
Parquet格式结合ZSTD压缩显著减少数据占用的空间,提高存储效率。
2、查询性能:
列式存储允许查询操作只读取必要的列,减少不必要的数据处理。
3、资源优化:
使用ZSTD压缩的数据可以在不牺牲查询性能的情况下节省计算资源和存储资源。
4、兼容性和灵活性:
支持广泛的查询引擎和计算框架,为数据处理提供高度的灵活性和兼容性。
应用案例
1、大数据仓库:
在构建大型数据仓库时,采用Parquet和ZSTD压缩可以有效管理海量数据,同时保持查询响应的速度。
2、云服务平台:
云平台用户可以通过配置Hive和Spark来利用Parquet和ZSTD,优化数据处理成本和性能。
3、日志处理系统:
对于日志数据的存储和分析,Parquet结合ZSTD提供了一种高效的解决方案,尤其是在需要长期存储和频繁查询的场景中。
未来展望与挑战
1、技术发展:
随着计算能力的提升和数据量的增加,Parquet和ZSTD的应用范围预计将进一步扩大。
2、安全性考虑:
数据压缩可能带来额外的安全需求,如加密压缩数据以保护敏感信息。
3、生态系统整合:
进一步整合Parquet和ZSTD到更多的数据处理工具和平台,提高整个生态系统的互操作性。
FAQs
如何在Hive中启用ZSTD压缩?
答:在Hive中启用ZSTD压缩主要涉及以下步骤:
1、确保Hive版本支持ZSTD压缩。
2、在Hive配置文件(如hivesite.xml)中设置hive.exec.compress.output为true启用输出压缩。
3、设置mapreduce.output.fileoutputformat.compress.codec为com.facebook.zstd.ZStandardCompressionCodec来指定使用ZSTD作为压缩编解码器。
4、重新启动Hive服务使配置生效。
ZSTD与其他压缩算法相比有何优势?
答:ZSTD(Zstandard)是一种高效的压缩算法,具有以下优势:
1、高压缩比:相比传统的Gzip和Snappy等压缩算法,ZSTD提供更高的压缩比,意味着相同数据量占用更少的存储空间。
2、快速解压速度:ZSTD不仅压缩效率高,还能提供快速的解压缩速度,这对于需要频繁访问的数据存储系统尤为重要。
3、可调的压缩级别:用户可以根据需要调整ZSTD的压缩级别,从低速压缩到高速压缩自由切换,满足不同场景下的需求。
通过这些优化和配置,可以最大化地发挥MapReduce存储中Parquet格式和Hive支持ZSTD压缩格式的优势,从而在大数据环境中实现更高效、更经济的数据管理和分析。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/900158.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复