


在当今大数据时代,MapReduce作为一种强大的数据处理工具,被广泛应用于数据分析、机器学习以及各种需要处理海量数据的场合,本文将深入探讨如何在Eclipse环境中配置和使用MapReduce,帮助读者更好地理解和应用这一技术。
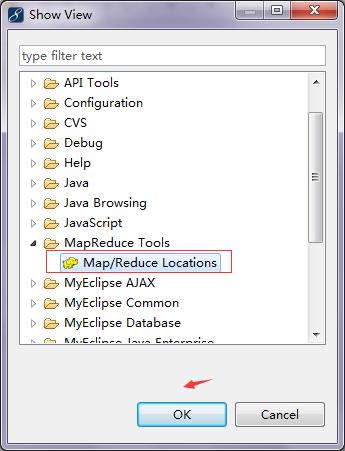

配置MapReduce开发环境
配置MapReduce的环境是开始使用MapReduce的第一步,需要确保你的系统满足基本的需求:安装有Java环境的操作系统和预装Eclipse的编程软件,重点在于为Eclipse安装Hadoop插件,这可以通过下载对应版本的hadoopeclipseplugin.jar文件并复制到Eclipse软件的插件目录下完成,具体步骤如下:
1、下载插件:根据你安装的Hadoop版本,下载对应的hadoopeclipseplugin.jar插件,如果你的环境中使用的是Hadoop 2.7.3,则需要下载hadoopeclipseplugin2.7.3.jar。
2、安装插件:将下载好的jar文件复制到Eclipse安装目录下的plugins文件夹中,复制完成后,重启Eclipse以便插件正确加载。
3、验证插件安装:Eclipse重启后,通过访问“Window——>Show View——>Other”选项,检查是否可以看到Map/Reduce视图,如果能看到,即表示插件安装成功。
新建MapReduce工程
配置好环境后,下一步是创建一个MapReduce工程,在Eclipse中,这可以通过以下步骤实现:
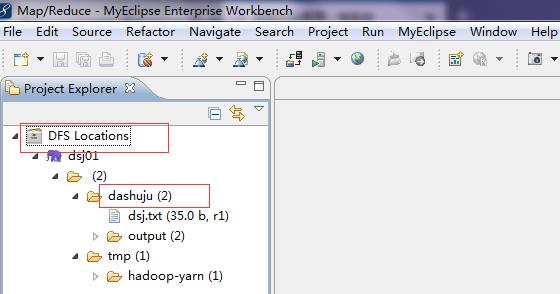
1、创建新项目:在Eclipse中选择“File——>New——>Project…”,然后从列表中选择MapReduce工程类型,输入项目名称和位置,点击Finish完成项目的创建。
2、配置MapReduce工程:在新创建的项目上右键单击,选择“Configure Hadoop”,在这里可以设置Hadoop安装路径、Hadoop版本以及其他相关配置,如MapReduce程序的主类等。
3、编写Map和Reduce代码:在项目中创建新的Java类,分别实现Mapper和Reducer函数,这些函数负责实现数据的映射和归约逻辑。
运行和调试
编写完Map和Reduce代码后,就可以准备运行和调试了,Eclipse使得这一过程变得非常简单:
1、配置运行参数:在项目上右键单击,选择“Run As——>Run Configurations…”,在弹出的窗口中设置Hadoop jar的路径和其他必需的运行参数。
2、运行MapReduce程序:配置完毕后,直接运行即可,你可以在Eclipse的控制台看到运行结果和可能的错误信息。
3、调试MapReduce程序:如果需要调试程序,可以在代码中设置断点,然后选择“Debug As——>Java Application”,Eclipse将允许你逐步执行代码,检查变量值等,帮助你找到问题所在。
通过上述步骤,用户可以在Eclipse环境下高效地开发和调试MapReduce程序,这不仅提高了开发的效率,也降低了学习和使用的门槛。
让我们通过一个具体的案例来进一步理解MapReduce的应用。
词频统计实例
词频统计是MapReduce的经典入门例子,该程序统计给定文本中每个单词出现的频率,实现这个程序,你需要定义一个Mapper来读取文本并输出单词及其频率,和一个Reducer来汇总相同单词的频率。
1、Mapper的实现:解析输入的文本数据,对每个出现的单词生成一个键值对,其中键是单词,值是该单词出现的次数。
2、Reducer的实现:接收所有相同键(单词)的值(次数),并进行汇总。
3、运行WordCount程序:在Eclipse中运行这个MapReduce任务,你将看到每个单词的总出现次数作为输出结果。
通过这个简单的实例,可以明显看到MapReduce处理大数据的强大能力与高效性。
FAQs
Q1: 在Eclipse中运行MapReduce程序时遇到连接Hadoop集群失败的问题怎么办?
A1: 确保你已经正确配置了Hadoop集群的连接参数,包括Hadoop主节点的地址和端口,检查网络连接是否正常以及防火墙设置是否允许Eclipse与Hadoop集群之间的通信。
Q2: 如何优化MapReduce程序的性能?
A2: 优化MapReduce程序性能可以从以下几个方面考虑:
合理设置数据输入格式和输出格式:根据数据的特性选择合适的格式,可以有效减少数据传输和解析的时间。
调整Map和Reduce任务的数量:根据集群的资源情况和数据量大小,适当调整并发任务的数量,可以达到更好的资源利用率和处理速度。
优化数据分区和排序:合理的数据分区和排序策略可以减少数据在网络中的传输量,提高整体的处理速度。
通过以上措施,你可以有效地提升MapReduce程序的性能,更快地处理大规模数据集。
在Eclipse环境下配置和使用MapReduce虽有其复杂性,但遵循正确的步骤和方法,可以极大地简化这一过程,从环境配置到项目创建,再到程序编写和调试运行,每一步都为高效处理大数据奠定了坚实的基础。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/899113.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复