

ORDER BY RAND()函数配合LIMIT子句。如果有一个名为table_name的表,可以使用以下查询来获取随机的100条记录:,,“sql,SELECT * FROM table_name ORDER BY RAND() LIMIT 100;,`,,这将返回表中的100条随机记录。这种方法在大型数据集上可能会比较慢,因为RAND()`函数会对每行数据进行计算。1、随机森林回归模型简介

定义与功能:随机森林是一种集成学习方法,它通过构建多个决策树来进行预测和分类,回归型的随机森林主要用于解决回归问题,即预测连续值的输出。
算法原理:该模型工作原理是基于boostrap抽样方法从原始数据集中抽取多个子集构建决策树,并对每棵树的结果进行平均以得到最终预测结果。
应用场景:随机森林回归模型广泛应用于金融分析、生物医药、环境科学等领域,用于预测例如房价、股价、疾病发展等连续变量。
2、MySQL数据库中的数据查询
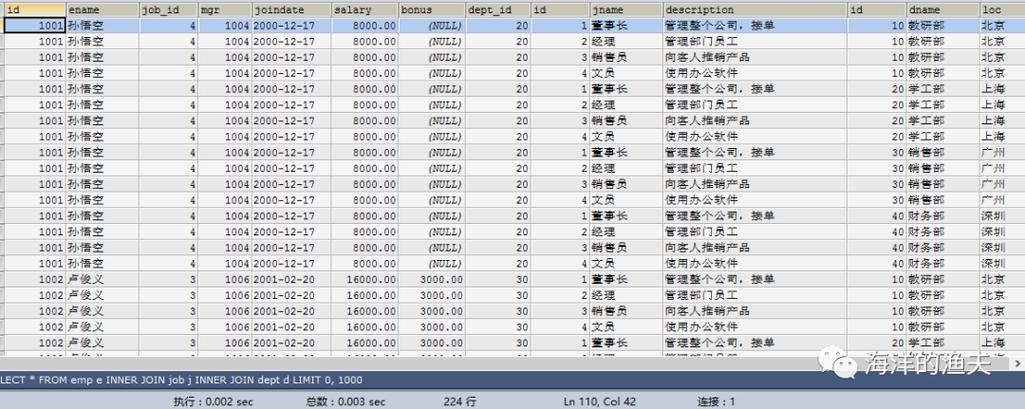
基本查询语法:在MySQL中,使用SELECT语句进行数据查询,可以指定具体的列或使用选择所有列。
查询中的索引优化:为了提高查询效率,通常需要在数据库表中的适当列上建立索引。
数据的过滤与排序:通过WHERE子句添加过滤条件,使用ORDER BY对结果进行排序,这对大型数据集的查询性能至关重要。
3、实现随机查询的方法
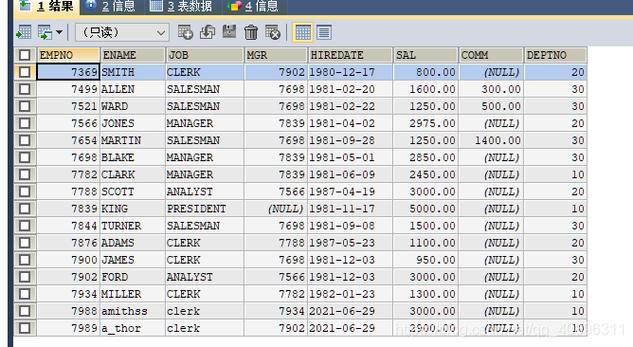
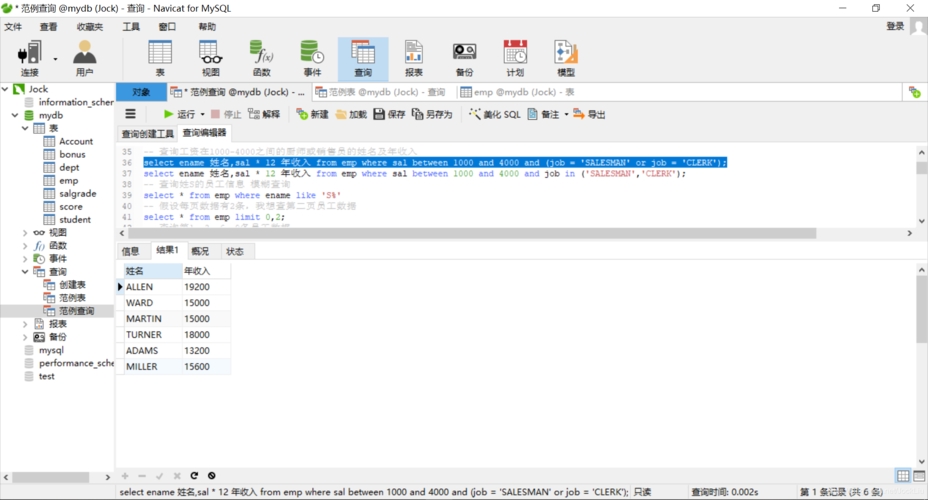
利用RAND()函数:MySQL中的RAND()函数可以对每一行生成一个随机数,结合ORDER BY可以实现数据的随机排序。
性能考量:尽管使用RAND()函数方便,但在处理大规模数据时可能效率较低,因为需要多次扫描数据列。
改进的随机查询策略:一种改进的方式是先计算出数据的总条数,然后在此基础上使用程序生成随机数作为LIMIT的参数,以此来获取随机记录。
4、随机森林回归模型的训练与应用
数据集的准备:训练随机森林回归模型前,需要准备包含特征和目标变量的数据集。
模型的训练:使用机器学习库(如scikitlearn)中的随机森林回归函数来训练模型。
模型的评估与应用:通过交叉验证和测试集评估模型效果,之后可以将模型应用于新的数据集进行预测。
5、分析查询结果与模型效果
查询结果的正确性:需要确保从数据库中查询得到的数据是正确和可靠的,这对于模型训练的准确性至关重要。
模型效果的衡量:通过计算模型的均方误差、决定系数等统计指标来评价模型的预测能力。
误差来源的分析:分析模型的预测误差来源,可能是数据质量问题、模型配置不当或数据本身具有不可预测的性质。
在深入了解上述内容后,还可以进一步探讨以下相关的知识点和注意事项:
优化数据库查询的常见做法包括查询缓存、数据库索引优化等。
在处理大数据时,考虑使用采样技术来减少数据处理的复杂度。
在选择数据时,应考虑到数据的代表性和多样性,以避免模型过拟合或欠拟合。
对于随机森林模型,调整其参数如树的数量、深度等可以影响模型的性能和泛化能力。
本文详细讨论了如何在MySQL数据库中查询随机数据以及如何将这些数据应用于随机森林回归模型的训练和应用过程中,理解这些步骤和策略对于有效使用数据库资源和构建准确的机器学习模型至关重要。
FAQs
如何在MySQL中使用RAND()函数进行随机查询?
在MySQL中,可以使用RAND()函数配合ORDER BY子句来实现随机查询,如果要从表中随机选取一条数据,可以使用如下SQL语句:
SELECT * FROM table_name ORDER BY RAND() LIMIT 1;
如果需要选取多条数据,只需将LIMIT后的数字改为所需的数量即可。
为什么在大数据量的情况下不推荐使用RAND()函数?
虽然RAND()函数提供了一种简便的方式来获取随机记录,但在处理大量数据时,使用RAND()函数会导致多次全表扫描,从而大大降低查询效率,在处理大型数据库时,推荐使用其他更高效的方法,如预先计算记录总数,再通过程序逻辑生成随机数来作为LIMIT参数。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/899075.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复