


在当今数据驱动的商业环境中,个性化推荐系统发挥着越来越重要的作用,协同过滤算法,特别是基于物品的协同过滤(Itembased Collaborative Filtering,简称ItemCF),因其在处理大数据环境下的有效性而广受关注,结合MapReduce框架实现的ItemCF能够高效地处理和分析大规模数据集,为数百万用户实时提供准确的推荐,本文将深入探讨如何利用MapReduce来实现物品协同过滤算法。
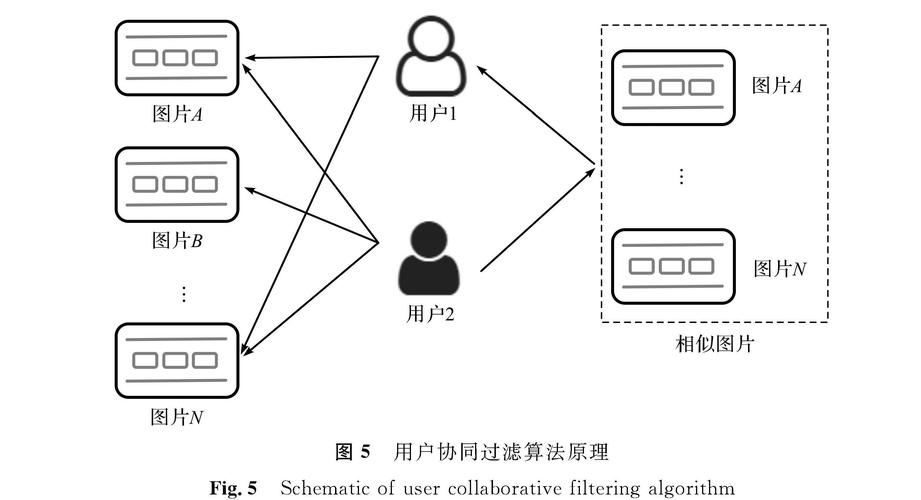

ItemCF简介
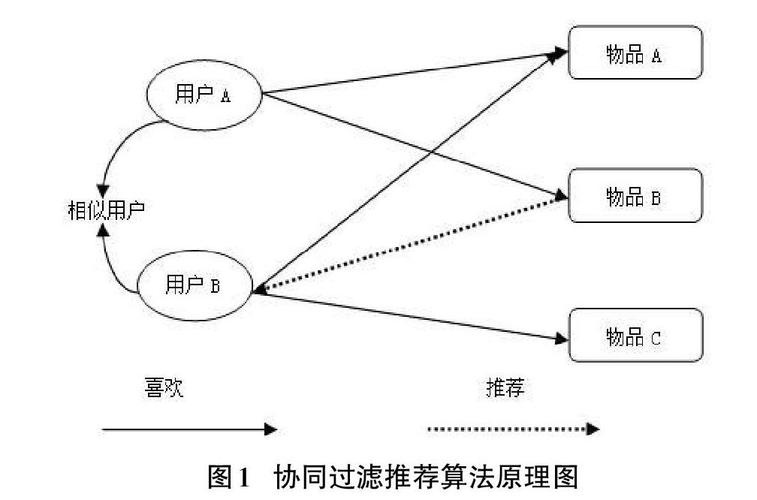
基于物品的协同过滤是通过分析用户对不同物品的评分来评估物品之间的相似性,并据此提供推荐的一种算法,就是向用户推荐与其之前喜欢的物品相似的物品,该算法的核心思想是,如果一个用户对一系列物品中的某几个表示喜欢,那么他可能也会对与这些物品相似的其他物品感兴趣。
MapReduce与ItemCF的结合
MapReduce是一种编程模型,用于处理和生成大数据集,它将任务分成两个阶段:映射(Map)和归约(Reduce),在ItemCF的实现中,MapReduce可以有效地处理大规模用户数据和物品数据,计算物品之间的相似度,并生成个性化推荐列表,以下是基于MapReduce的ItemCF算法的详细步骤:
1、读取原始数据:此步骤涉及加载用户行为数据,如评分数据,然后将其按用户ID分组,这一步是为了理解每个用户对哪些物品有评分,以及具体的评分数值。
2、统计物品同时出现的次数:这一阶段通过Mapper组件实现,输出那些被同一用户评分的两个物品的组合及同时评分的次数,这是计算物品间相似度的基础。
3、生成评分矩阵:使用Mapper生成用户评分矩阵和物品同现矩阵,这两个矩阵是后续计算物品相似度和生成推荐的关键数据结构。
4、计算推荐结果:最后一步是通过矩阵乘法来实现,即物品的同现矩阵A乘以用户对物品的评分矩阵B,得到的结果即为最终的推荐列表,其中包含了为用户推荐的Top N个相似物品。
推荐系统的实际应用
电子商务网站如亚马逊已经成功地将ItemCF算法应用于其推荐系统中,据报道,这为亚马逊带来了至少30%的销售额,这一数字充分证明了基于MapReduce的ItemCF算法不仅在理论上有效,而且在实践中也具有极高的商业价值。
性能优化策略
虽然MapReduce为处理大规模数据集提供了强大的支持,但为了进一步提升ItemCF的性能,可以考虑以下优化策略:
数据预处理:在运行MapReduce作业之前,适当地清洗和转换数据可以减少计算过程中的处理负担。
优化MapReduce作业配置:根据具体需求调整Map和Reduce任务的数量,以达到最佳的负载平衡和资源利用。
使用高效的数据存储格式:比如Parquet和ORC等列式存储格式,可以加快数据的读写速度。
基于MapReduce的ItemCF算法为处理大规模推荐问题提供了一个高效、可扩展的解决方案,通过合理设计和优化,可以在保证推荐质量的同时,显著提升系统的响应速度和处理能力。
相关问答FAQs
为什么选择基于物品的协同过滤而不是基于用户的协同过滤?
基于物品的协同过滤(ItemCF)相较于基于用户的协同过滤(UserCF),在物品数量相对稳定且少于用户数量的情况下,能提供更稳定和准确的推荐,因为物品间的相似度变化不如用户兴趣的变化频繁,所以ItemCF在实时性和准确性上表现更好。
MapReduce在处理大规模数据时有哪些优势?
MapReduce的优势在于其简单而强大的数据处理模式,它能够轻松地扩展到多个服务器上进行并行计算,这使得它非常适合于处理TB甚至PB级别的大规模数据集,有效地解决了单机处理能力的瓶颈问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/898005.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复