


MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它通过将任务分解为多个小任务,分布到不同的服务器上进行并行处理,再将结果汇总,以此达到快速处理大量数据的目的,这种模型特别适用于数据处理和分析任务,如日志分析、数据挖掘等,本文旨在深入解析MapReduce的工作原理及其在实际应用中的表现,尤其以WordCount为例来具体展示其操作流程。
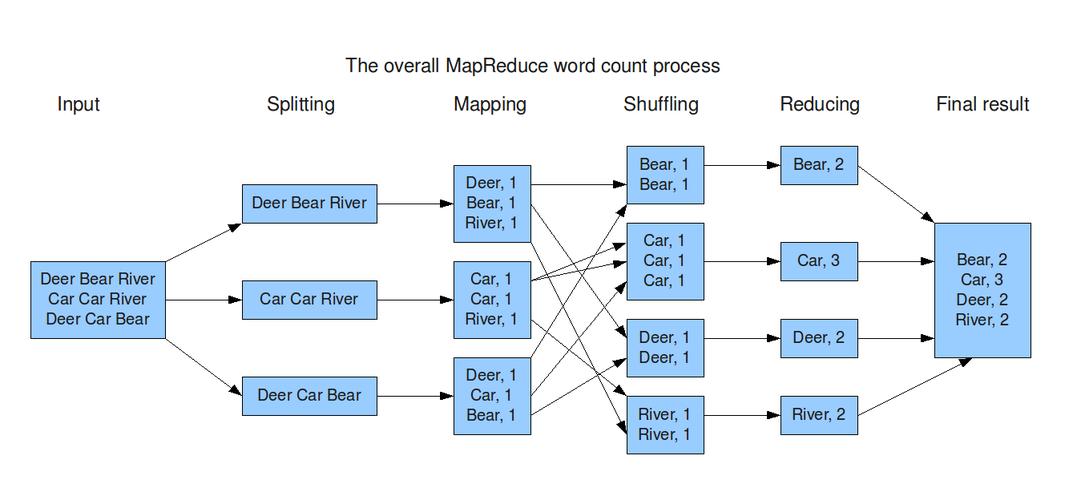

MapReduce的核心思想可以概括为用户自定义的Map函数和Reduce函数,Map函数负责处理输入数据,生成一组中间键值对;而Reduce函数则用于合并所有这些与特定键相关的中间值,以得到最终的输出结果,这一过程隐藏了分布式存储、工作调度、负载均衡、容错处理及网络通信等复杂性,极大地简化了程序员的工作负担。
在Map阶段,框架自动将输入数据划分为多个分片,并为每个分片创建一个map任务,这些任务可以在不同的服务器上并行执行,每个map任务都会处理其分配的数据分片,并执行用户定义的Map函数,从中提取出键值对,在WordCount程序中,Map函数会读取文本数据,并针对每个单词生成一个(key/value)对,其中key是单词,value是该单词出现的次数。
接下来是Shuffle阶段,这是MapReduce框架自动进行的一个环节,主要负责对Map阶段的输出进行排序和传输,这个阶段将具有相同键的值聚集在一起,为接下来的Reduce阶段做准备,通过这样的方式,所有相同的键会被发送到同一个Reduce任务。
Reduce阶段,每个Reduce任务会接收到来自不同Map任务的键值对,它会遍历这些键值对,对于每一个独特的键,它都会调用一次用户定义的Reduce函数,以合并值并生成最终的结果,在WordCount例子中,Reduce函数会将所有相同单词的出现次数进行累加,得到该单词的总出现次数。
下面通过一个FAQs部分来解答有关MapReduce的常见疑问:
FAQs
1. MapReduce中的Map函数和Reduce函数有何区别?
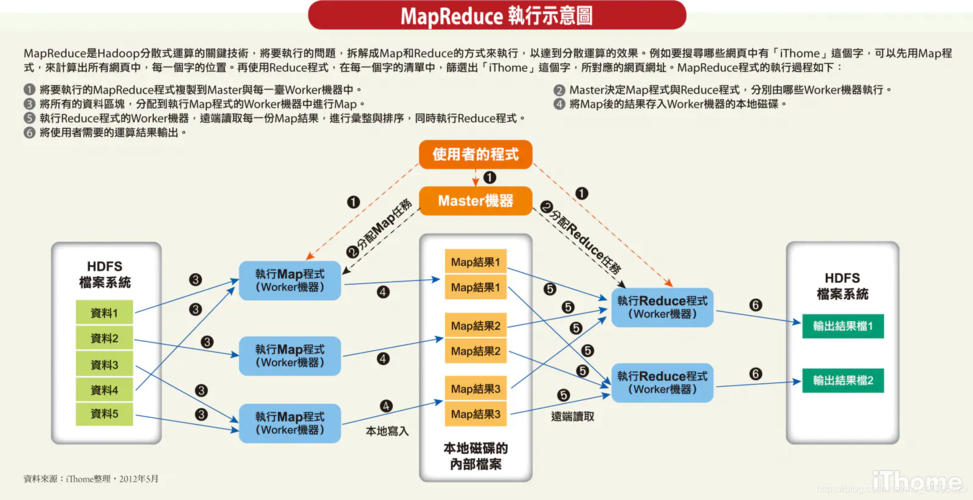
Map函数主要负责数据的预处理,如数据的过滤和初步的聚合,输出中间键值对供后续处理使用。
Reduce函数则聚焦于对拥有相同键的多个值进行处理,如统计和汇总,以得出最终结果。
2. MapReduce如何处理硬件故障?
MapReduce设计时考虑了硬件故障的可能性,通过任务的重试机制和数据备份来保证计算任务的顺利完成,如果某个任务失败,框架会自动在其他节点上重新执行该任务。
MapReduce作为一种强大的分布式处理框架,通过简单的Map和Reduce两个函数,就可以完成复杂的数据处理任务,它的高效性和易用性使其在处理大数据领域得到了广泛的应用,通过了解其内部工作机制,用户可以更有效地编写和优化MapReduce作业,从而在数据分析和处理方面取得更好的成绩。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/897562.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复