


在大数据技术领域,HBase作为一个高性能、可扩展的分布式存储系统,广泛应用于需要高速读写大数据场景,MapReduce则是一种编程模型,用于大规模数据集的并行处理,将HBase与MapReduce结合使用,可以实现复杂的数据处理任务,如数据分析、数据转换等操作,本文旨在详细解析如何通过MapReduce从HBase读取数据,并将处理结果重新写入HBase的过程。

数据准备
确保HDFS和HBase已经启动,可以通过运行startdfs.sh 和starthbase.sh 命令来启动这些服务,进入HBase shell命令行,创建一个用于输入数据的表,可以创建一个名为word的表来存储文本数据。
MapReduce作业编写
当编写MapReduce作业以读取或写入HBase时,建议使用TableMapper 和/或TableReducer 的子类,这有助于简化代码并提高其可读性和可维护性,可以使用IdentityTableMapper 和IdentityTableReducer 这两个无作用传递类作为基本用法的参考。
HBase提供了TableMapReduceUtil 工具类,可以直接被使用来初始化表和映射器(mapper)的配置,具体地,你需要提供表名、Scan对象、mapper的class对象、输入输出类型的class对象以及job对象。
TableMapReduceUtil.initTableMapperJob(
"myTable", // 表明
scan, // Scan类
MyMapper.class, // 关联mapper方法
MyKey.class, // 输入的key类型
Text.class, // 输入的value类型
job // job
); ZK授权
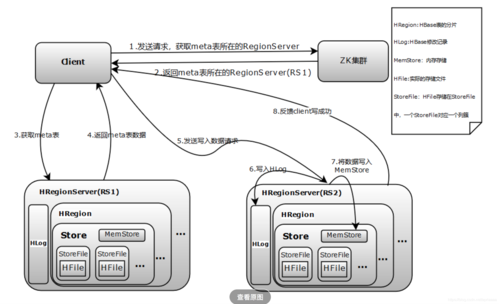
由于HBase强依赖于Zookeeper(ZK),访问HBase表之前通常需要通过访问ZK得到授权,特别是在大量并发访问时,避免因连接数过多而导致的服务不稳定。
MapReduce与HBase的结合
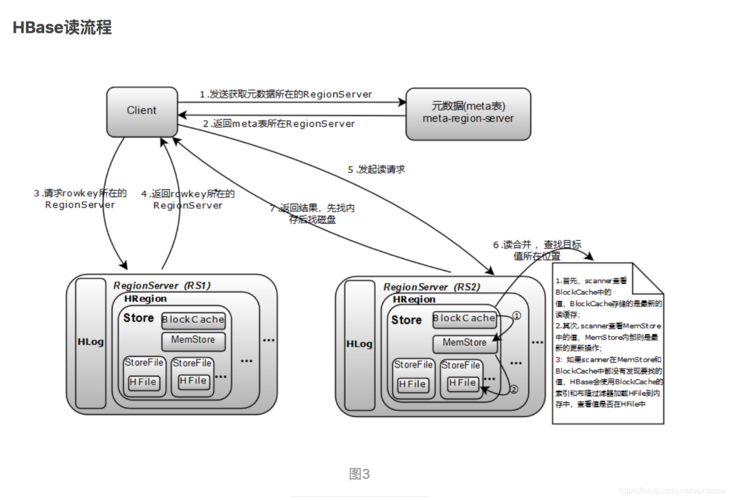
在处理大数据时,MapReduce能够高效地操作HBase中的数据,HBase Table和Region的关系类似于HDFS File和Block的关系,HBase提供的TableInputFormat 和TableOutputFormat API允许开发者方便地指定HBase Table作为MapReduce作业的源(Source)和目标(Sink),这意味着开发者基本上不需要关注HBase系统的细节,从而能更专注于数据处理逻辑本身。
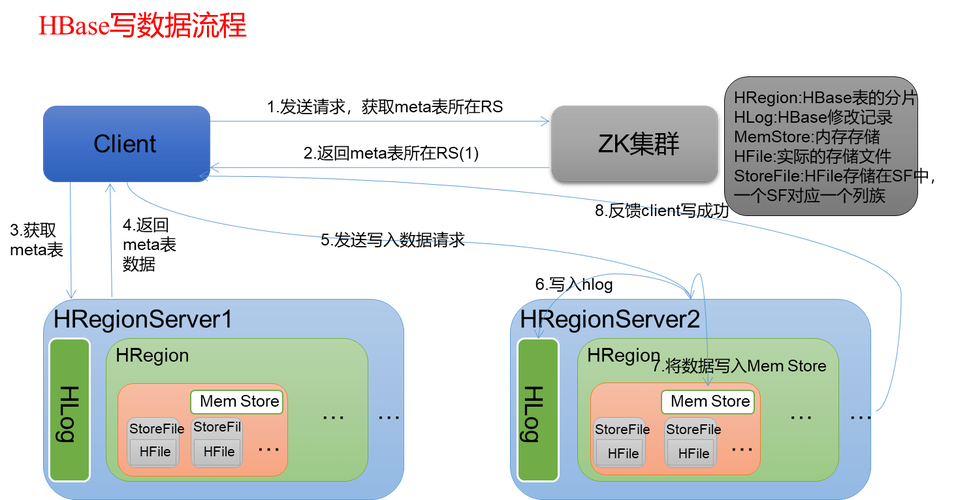
通过上述步骤,可以实现通过MapReduce从HBase读取数据的任务,数据处理完成后,可以将结果再次写入HBase,这一过程同样利用MapReduce框架的TableOutputFormat 类来实现,这样,不仅实现了数据的高效读取,还能将处理后的数据有效地整合回HBase系统中。
相关问答FAQs
如何在MapReduce作业中处理HBase的数据权限问题?
确保在进行HBase表的操作前,通过ZK进行适当的授权,这可以通过编程方式在MapReduce作业初始化阶段实施,以避免未授权的访问错误。
MapReduce作业执行过程中遇到性能瓶颈应该如何优化?
可以考虑优化HBase表的设计,比如预分区和合理的行键设计,合理调整MapReduce作业的配置参数,如内存分配、并发任务数等,也可以显著提升作业执行的性能。
通过以上详细解析,您应已对如何使用MapReduce从HBase读取数据并再次写入HBase有了全面的理解,这种技术组合为处理大规模数据集提供了一个强大而灵活的工具,特别适合于需要复杂数据处理的场景。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/896966.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复