


在MySQL中,链表查询是一种常见的数据库操作,用于从多个表中获取数据,这种查询方式经常会出现数据重复的问题,尤其是在涉及一对多关系的表中,本文将探讨如何有效地在链表查询中去重,避免设计冗余用例,并提高查询效率。
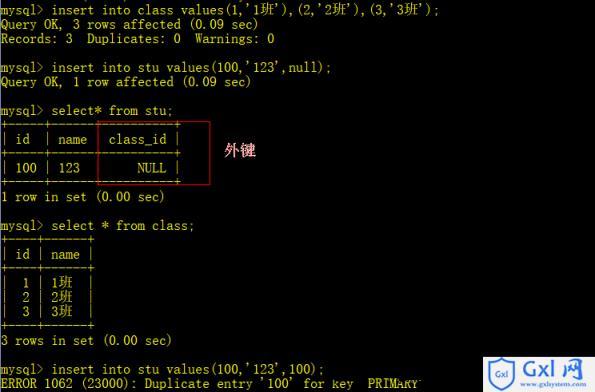

理解为何链表查询会产生重复是解决问题的第一步,在进行JOIN操作时,如果关联的字段不是唯一的,那么就可能在结果集中产生重复的数据行,当一个学生选修多门课程时,如果直接将学生表和课程表进行连接,每个学生的信息会与其选修的每门课程各重复一次,这种情况在处理大数据表时尤为突出,可能导致性能下降甚至查询失败。
解决这一问题的有效方法之一是使用DISTINCT关键字,通过在SELECT语句中加入DISTINCT,可以确保返回的结果集中,每个学生的信息只出现一次,无论他选修了多少门课程,这种方法简单易用,适合去除简单的重复情况。
另一种更为灵活的方法是使用GROUP BY子句,通过GROUP BY可以将结果集按照一个或多个列进行分组,从而避免因连接而产生的重复,在实际应用中,可以使用GROUP BY结合聚合函数(如COUNT(), MAX(), MIN()等),不仅去重,还可以对分组后的数据进行分析处理。
对于更复杂的查询需求,子查询是一个有效的工具,子查询允许你先执行一个查询来筛选或重组数据,然后再将结果集与另一个表进行连接,这样,可以在进行最终的连接操作前预先消除一部分重复数据,减少计算量。
除了上述技术手段,开发者还应该养成良好的SQL编写习惯,在设计数据库结构时,尽量保持数据的规范化,避免不必要的数据冗余,在编写查询语句时,及时检查关联字段的唯一性,选择合适的连接类型(如内连接、左连接或右连接),这些都有助于提高查询效率并减少重复数据的产生。
针对链表查询的性能优化,了解和利用好索引也极为关键,正确地建立和使用索引可以显著提高查询速度,特别是在处理大表时,应定期分析查询性能,适时调整索引策略以适应数据的变化。
避免链表查询中的重复数据需要综合运用多种技术和策略,从使用DISTINCT关键字和GROUP BY子句去重,到应用子查询优化查询结构,再到培养良好的数据库设计和查询编写习惯,每一种方法都有助于提升数据处理的效率和准确性,随着技术的发展,还有更多的高级技巧和工具可以被用来进一步优化查询性能。
相关问答FAQs
如何在MySQL中使用DISTINCT关键字进行去重?
使用DISTINCT关键字非常简单,只需要在SELECT语句中加入DISTINCT,然后列出你需要去重的字段。SELECT DISTINCT column1, column2 FROM table_name; 这样就可以确保结果集中的column1和column2的组合是唯一的。
在使用GROUP BY进行分组查询时,有哪些常用的聚合函数?
常用的聚合函数包括COUNT()用于计数,SUM()和AVG()分别用于计算总和和平均值,MAX()和MIN()用于找出最大值和最小值,这些函数可以帮助你在分组后对数据进行进一步的分析和处理。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/895779.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复