


MapReduce Shuffle原理
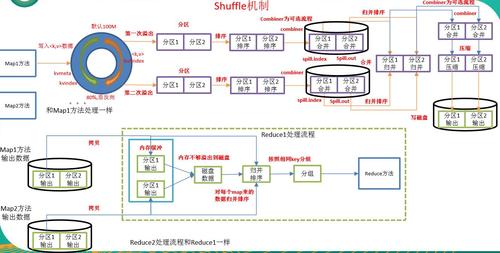

Shuffle过程是MapReduce框架中数据从Map阶段传递到Reduce阶段的一个关键步骤,它确保了数据能够按照特定的规则,从Map端的无序输出变为Reduce端可处理的有序数据,这一过程不仅涉及数据的分区和排序,还包含局部聚合、缓存、拉取及再合并排序等核心机制。
1、Map端的角色与功能
在Map阶段的结尾,每个Map任务将产出大量的键值对,这些键值对首先被写入一个环形缓冲区,默认情况下,这一缓冲区的大小为100MB,但可以根据具体硬件配置调整以优化性能。
当环形缓冲区达到一定阈值时,其内容会被溢出写到磁盘上,形成一个溢出文件,这个过程中的分区和排序是必不可少的,因为Reduce任务需要按分区来处理特定范围内的键,且每个分区内的数据必须是有序的。
2、Reduce端的角色与功能
一旦Map端完成数据处理并写出溢出文件,Reduce端就可以开始从各个Map任务所在的节点拉取属于自己的数据,这个过程中,Reduce任务会根据分区信息定位到相应的Map输出文件。
拉取到数据后,Reduce任务会将这些数据进行合并和排序,以确保最终进入Reduce函数的数据是有序的,这有助于处理数据时的高效性,例如进行分组或连接操作。

调优策略
调整内存和缓冲区大小:根据具体环境调整mapreduce.task.io.sort.mb参数可以提高数据处理效率,增大此参数可以减少磁盘IO操作,从而提速。
合理设置分区:自定义Partitioner接口可以实现更合理的数据分配,解决数据倾斜问题,通过合理分区,可以确保各Reduce任务负载均衡,避免某些节点过载而影响整体处理速度。
相关问答FAQs
1、如何理解MapReduce中的Shuffle过程?
Shuffle过程可以视为MapReduce框架中数据的“重新洗牌”和“排序”阶段,它负责将Map任务的输出按照Reduce任务所需的格式重新组织,包括数据的分区、排序和必要的压缩等操作。
2、Shuffle过程中数据是如何流动的?
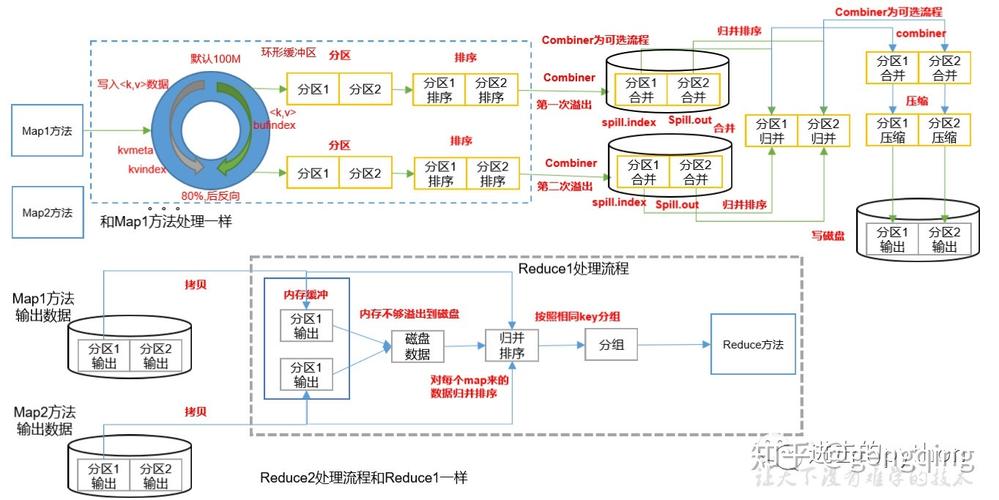
数据首先在Map端生成,存入环形缓冲区并定期写入磁盘,之后,Reduce端通过网络从各个Map端拉取属于自己处理范围的数据,进行合并和排序,最后交给Reduce任务处理。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/895534.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复