


在大数据领域,MapReduce框架的使用是至关重要的,下面将通过两个具体的统计案例来详细解析MapReduce编程范式的应用:
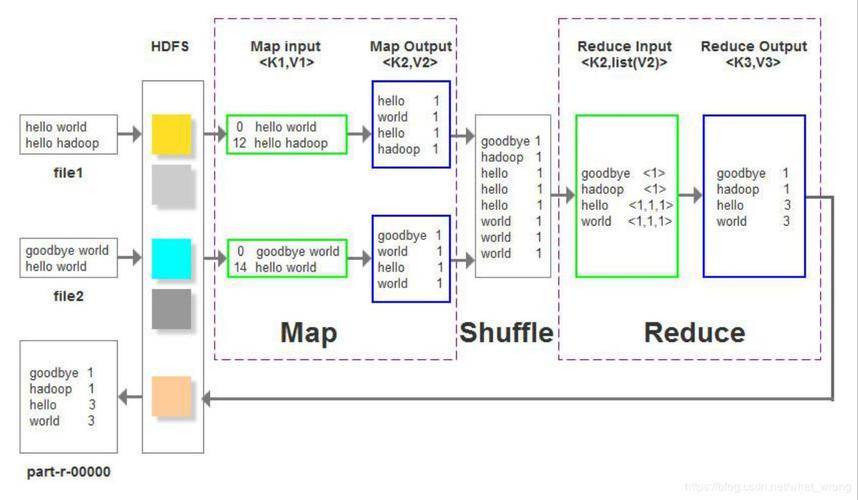

1、好友对数统计
数据准备与需求分析:假设有一个friends.txt文件,每一行表示一对好友关系,如“华仔,郭靖”,任务是要统计去重后的好友对数。
实现逻辑:Map阶段,读取文件中的每一行,并为每一对好友生成一个键值对,其中键是这对好友的排序字符串(保证唯一性),值是数字1,经过Shuffle和Sort阶段,具有相同键的值会被集中到一起,在Reduce阶段,对每个键的值进行汇总,最终得出总的好友对数。
2、词频统计
数据准备与需求分析:文本数据中需要统计每个单词出现的频率,给定一段文本“hello world hello”,目标是得到“hello”和“world”各自的出现次数。
实现逻辑:Map阶段,将文本分割成单词,并为每个单词生成一个键值对,其中键是单词,值是1,在Shuffle和Sort阶段,所有相同键的值(即同一个单词)被归集到一起,Reduce阶段,对每个键的值进行累加,得到每个单词的总出现次数。
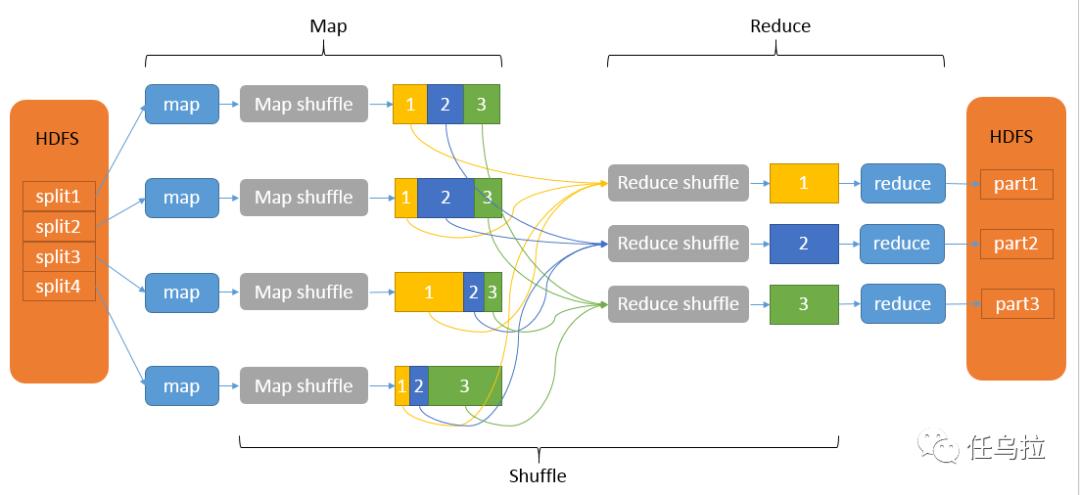
通过以上两个实例,可以发现MapReduce模型的强大之处在于其简单的编程模型以及强大的分布式计算能力,适用于处理大量数据的场景,可以有效地进行并行处理,提高运算效率,MapReduce模型也有其局限性,比如实时处理能力较弱,不适合需要频繁交互的场景,对于数据和计算过程中需要维护状态的情况,使用MapReduce也会比较困难。
提供一个相关的FAQs部分,帮助解决一些常见的疑问:
FAQs
1、Q: MapReduce程序在执行时如何保证数据的一致性和容错性?
A: MapReduce通过多种机制确保数据处理的一致性和系统容错性,在Map阶段,输入数据会分成多个数据块,每个数据块由不同的Map任务处理,其间互不影响,在数据传输过程中,采用冗余策略防止数据丢失,在Reduce阶段,即使某个Reduce任务失败,也可以重新执行该任务而不影响整体结果。
2、Q: MapReduce适用于所有大数据处理场景吗?
A: 不是所有场景都适合使用MapReduce,对于那些需要实时响应或者数据量不大的任务,使用MapReduce可能会因为其较高的开销而不太划算,对于需要频繁读写操作的任务,考虑其他模型如Apache Spark可能更合适,因为它提供了更加灵活的数据操作方式和更快的处理速度。
MapReduce作为一个高效的大规模数据处理框架,通过分布式计算极大地提高了处理速度,特别适合于批量处理大量数据,根据实际应用场景的具体需求选择合适的工具也非常重要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/893648.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复