


在当今大数据时代,处理大规模数据集已成为常态,MapReduce框架作为一种广泛用于数据处理的模型,能够有效地处理和分析海量数据,在数据库操作中常见的一种需求是将两个或多个表通过某个公共字段连接起来,即所谓的JOIN操作,本文将深入探讨在MapReduce框架中实现JOIN操作的方法,特别是ReduceSide Join技术,其工作原理、实现方式以及具体案例。
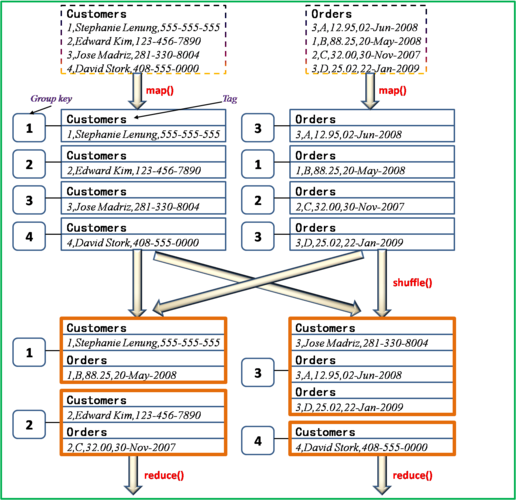

基本原理与工作方式
ReduceSide Join是MapReduce框架中实现表连接的一种方法,它将连接操作的负担从Map阶段转移到了Reduce阶段,在Map阶段,来自不同文件的数据被标记并输出,以便于在Reduce阶段进行区分和合并处理。
Map端的主要工作
在Map阶段,其主要任务是为来自不同数据源(例如不同的文件或表)的key/value对打上标签,这一步骤至关重要,因为它区分了数据的来源,之后,Map函数使用连接字段作为key,而其他信息及新加的标志则作为value部分输出。
Reduce端的主要工作
到了Reduce阶段,由于key已经按照连接字段进行了分组,因此来源不同的记录自然地聚集在一起,Reducer的任务就相对简单:它只需识别这些带有标签的记录,将它们按照既定的逻辑关联起来即可完成数据的合并操作。
操作示例与案例分析
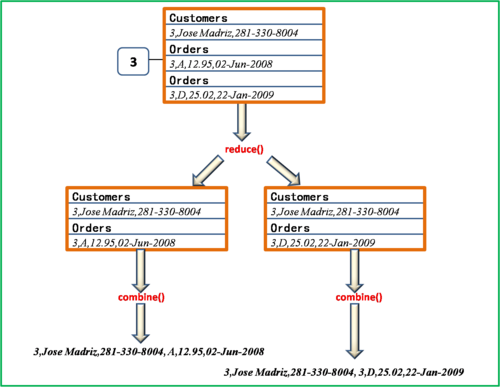
为了更清晰地理解ReduceSide Join的具体实现,我们可以通过一个具体的案例来展示其工作流程,假设有两个数据集,一个是员工的基本信息,另一个是员工的工作记录。
需求
需要找出每个员工的姓名及其对应的工作记录。
实现
在Map阶段,对两个文件中的记录根据员工ID打上标签,quot;Emp_"和"Record_",然后这些记录会通过员工ID作为key发往同一个Reduce任务,在Reduce端,只需要将这些携带有"Emp_"和"Record_"标签的记录根据员工ID合并,即可得到每个员工的名字及其所有的工作记录。
优势与挑战
使用ReduceSide Join处理数据连接操作提供了几个显著的优势,但同时也面临一些挑战:
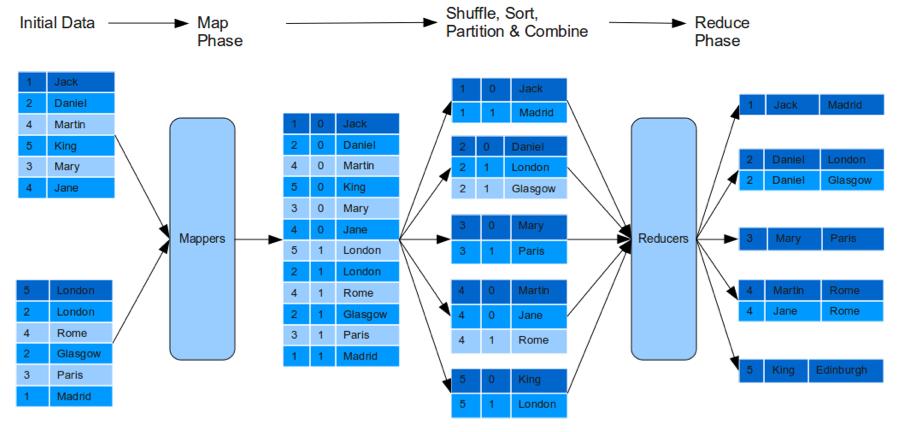
优势
1、简化处理:将复杂的连接操作转移到Reduce阶段进行,简化了Map阶段的处理负担。
2、高效性:减少了网络传输的数据量,因为只有必要的数据被发送到Reducer。
3、扩展性:适用于大规模数据集,因为MapReduce框架本身具有良好的扩展性和容错性。
挑战
1、数据倾斜问题:如果某些key值非常频繁,可能会导致某些Reduce任务处理的数据量过大,影响整体性能。
2、内存消耗:在处理大量数据时,Reducer可能需要较大的内存空间来存储和处理数据。
总体而言,ReduceSide Join是MapReduce框架中一个强大且常用的数据处理模式,特别适合处理大规模的数据集合并问题,通过合理的设计和优化,可以极大地提高数据处理的效率和准确性。
相关问答FAQs
Q1: ReduceSide Join是否适合所有类型的JOIN操作?
A1: 虽然ReduceSide Join非常适合处理大数据集中的等值连接(equijoin),但对于非等值连接或其他更复杂的连接条件,可能需要更复杂的逻辑或者不同的实现策略。
Q2: 如何优化ReduceSide Join的性能?
A2: 可以通过优化数据分区和确保数据均匀分布来减少数据倾斜问题,同时合理配置MapReduce的资源参数,如内存大小和Reducer的数量,也是提升性能的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/893482.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复