


在当今大数据处理领域,Hadoop MapReduce框架广泛被用于处理大规模数据集,为了提高数据处理的效率和速度,Hadoop为MapReduce提供了一种分布式缓存机制,允许用户将所需文件分发到各个执行任务的子节点上,从而实现数据的本地访问和处理,本文将深入探讨如何配置和使用Hadoop的分布式缓存来执行MapReduce任务,旨在帮助读者更好地理解其工作原理、配置步骤和注意事项。
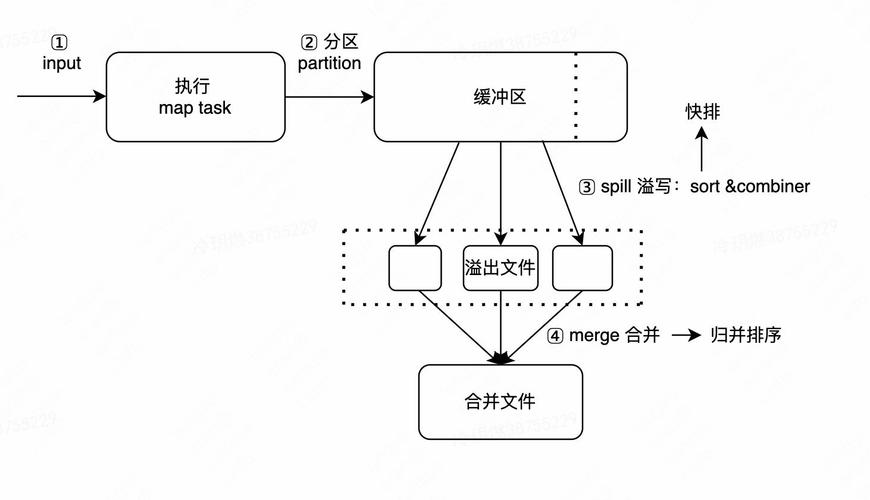

了解分布式缓存的基本概念是基础,Hadoop的分布式缓存(DistributedCache)是一种特殊机制,用于在MapReduce任务执行过程中共享和重用数据,通过将需要缓存的文件分发到每个执行任务的节点机器中,各节点可以直接从本地文件系统读取数据,从而避免了通过网络重复传输相同数据的开销,提高了整体性能。
我们探讨如何配置和使用分布式缓存:
1、准备工作:确保所需缓存的文件已存储在HDFS上,这是因为DistributedCache仅支持分发存储在HDFS上的文件。
2、设置符号连接:为了便于在MapReduce程序中直接访问这些文件,可以在原HDFS文件路径后加上“#somename”来设置符号连接,这样,在程序中只需通过简单的文件名即可访问这些缓存文件。
3、编程时使用:在MapReduce程序里,通过DistributedCache.getLocalCacheFiles()方法获取缓存文件的本地路径,之后,便可以像处理普通文件一样对这些文件进行读写操作。
4、注意事项:
文件只读:通过DistributedCache分发的文件在各个节点上是只读的,不能进行写操作。

避免大文件:不要分发过大的文件,文件分发会在执行任务之前进行,太大的文件会影响任务的启动速度。
限制文件大小:建议缓存文件的大小不宜过大,以免影响分布式缓存的效率。
我们通过一个表格归纳分布式缓存的配置步骤及其相应的要点:
| 步骤号 | 步骤描述 | 要点 |
| 1 | 确保文件已存储在HDFS上 | DistributedCache仅分发HDFS上的文件 |
| 2 | 在HDFS文件路径后设置符号连接 | 如:“hdfs://path/to/file#filename” |
| 3 | 在MapReduce程序中使用DistributedCache API获取文件路径 | 使用DistributedCache.getLocalCacheFiles()获取本地路径 |
| 4 | 注意文件的只读属性 | 分发的文件在节点上是只读的 |
| 5 | 考虑文件大小对任务启动的影响 | 避免分发过大的文件,以免影响任务启动速度 |
在配置和使用分布式缓存时,还需要考虑一些高级选项和最佳实践,比如检查是否开启了符号连接支持、选择合适的文件大小和格式以优化性能等。
h3. 相关问答 FAQs
Q1: 分布式缓存中的文件是否可以在MapReduce任务中修改?
A1: 不可以,通过分布式缓存分发到各个节点的文件是只读的,不能在MapReduce任务中进行修改。
Q2: 如果分发的文件不存在或损坏会怎么样?
A2: 如果分发的文件不存在或在传输过程中发生错误导致文件损坏,那么在使用DistributedCache.getLocalCacheFiles()方法获取文件时可能会抛出异常,使用前应检查文件的完整性和可用性。
通过上述讨论,我们了解了Hadoop MapReduce中分布式缓存的配置和使用方法,以及相关的注意事项和常见问题解答,正确地使用分布式缓存不仅可以提高数据处理效率,还可以让MapReduce程序更加灵活和强大,希望这些信息能够帮助读者更好地理解和应用分布式缓存技术。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/891942.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复