


TFIDF(Term FrequencyInverse Document Frequency)是一种统计方法,用以评估一个词或短语在文档集中的重要程度,它的基本思想是:如果某个词或短语在一篇文章中出现的频率(TF)高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类,这个算法常被用于文本挖掘和信息检索中,帮助理解大量文本数据的关键信息,本文将详细解析如何通过MapReduce框架实现TFIDF算法。

算法原理及组成
1、词频(TF, Term Frequency): 指某个词在文档中出现的次数,这个数字通常会被正规化,以防止长文件对词的频率产生偏差影响。
2、逆文档频率(IDF, Inverse Document Frequency): 由总文档数除以包含该词的文档数目,然后取对数得到,IDF的引入是为了减少那些常见但信息量小的词的权重。
3、TFIDF值: 最终的TFIDF值是由上述两者的乘积得出,这个数值能够有效地反映出这个词在文档中的重要程度以及区别不同文档的能力。
MapReduce实现步骤
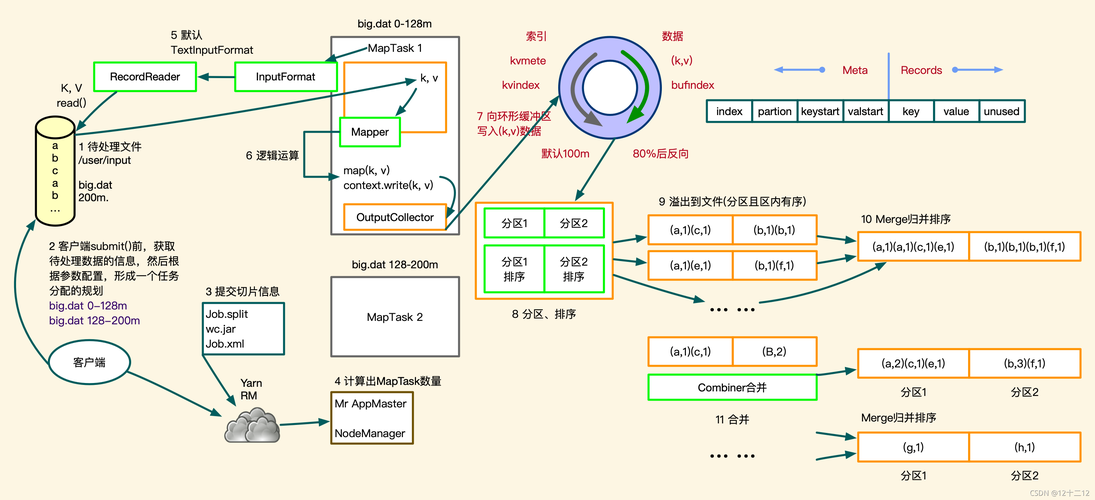
MapReduce是一种编程模型,用于处理和生成大数据集的相关实现,在处理TFIDF算法时,可以分为以下几个关键步骤:
1、数据预处理: 包括清洗数据、去除停用词等,确保输入数据的质量和准确性。
2、计算TF (词频):
Mapper阶段: 每个Mapper任务处理文档集中的一部分,计算每个词的出现次数。
Reducer阶段: 累计来自不同Mapper的同类词的出现次数,得到每个词的总出现次数,进而计算TF值。
3、计算IDF (逆文档频率):
同样通过一系列的Mapper和Reducer任务,首先统计每个词出现在多少个文档中,然后计算IDF值。
4、整合TF与IDF:
最后一个阶段是将TF和IDF的结果进行整合,通过乘法运算得出最终的TFIDF值。
5、输出结果: 将每个词的TFIDF值输出,作为文本分析的依据。
实现细节与核心组件
TFMapReduceCore类: 包含计算TF的核心逻辑,主要负责词频的统计与计算。
IDFMapReduceCore类: 包含了IDF的核心计算逻辑,用于统计词在整个文档集的分布情况并计算其逆文档频率。
IntegrateCore类: 负责将TF和IDF的结果进行整合,计算出最终的TFIDF值。
应用场景
1、文本挖掘: 在大量的文本数据中提取高质量的信息,如关键词提取、文档摘要等。
2、搜索引擎优化: 提高搜索结果的相关性,通过分析用户的查询意图与文档库中的文档匹配度来优化搜索结果。
3、广告推送: 根据用户的历史数据和行为分析,精准推送相关广告内容,增强用户体验与满意度。
FAQs
Q1: MapReduce实现TFIDF的优势是什么?
A1: MapReduce模型允许分布式处理大规模数据集,可以有效地并行处理海量文本数据,提升计算效率和处理速度,特别适合于大数据环境下的文本分析和处理任务。
Q2: 如何处理多语言文本在使用TFIDF时的挑战?
A2: 对于多语言文本,首先应使用适当的分词工具进行分词,确保每种语言都能正确处理,考虑使用语言特定的停用词列表和适当的正则表达式来改进文本预处理过程,以提高多语言文本分析的准确性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/891887.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复