


在MapReduce框架中,Shuffle过程是连接Map和Reduce阶段的关键环节,主要负责数据的重新分配,本文将深入探讨MapReduce中的Shuffle调优技巧,以期提高整体作业性能,具体内容如下:
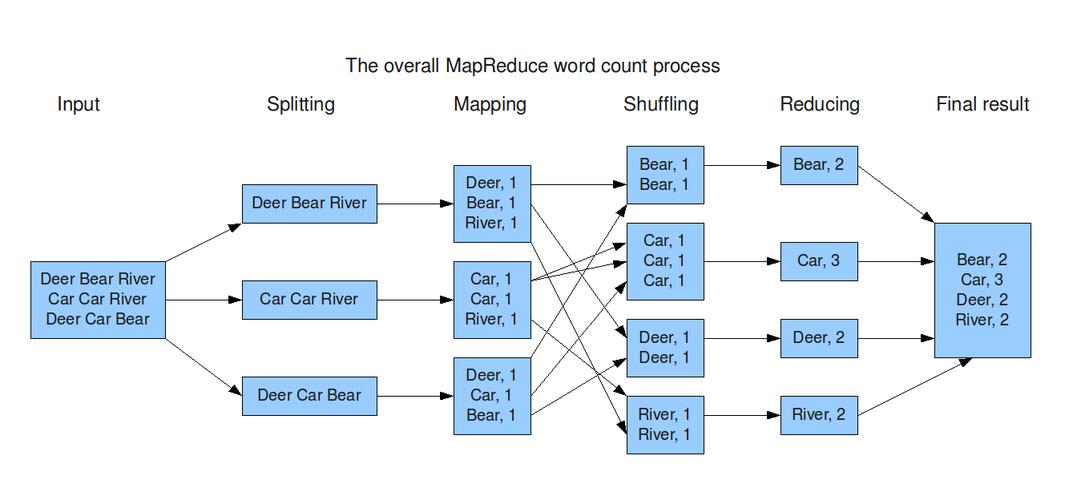

1、理解Shuffle过程
Map端的输出处理:在Map阶段完成后,其输出结果需要按key进行排序,并存入本地磁盘,每个Map任务会生成一个RDD文件,该文件里包含了所有输出的键值对。
Reduce端的数据拉取:Reduce任务开始时,它会从每个Map任务的输出文件中拉取与其相关的数据,此过程中,Reduce任务会从多个Map任务处获取数据,并对拉取到的数据进行合并排序。
2、Shuffle调优的重要性
资源消耗:Shuffle过程中涉及大量的磁盘IO、网络传输以及排序操作,这些都是资源密集型的操作,尤其是对CPU和IO资源的消耗较大。
性能瓶颈:由于Shuffle过程资源消耗大,它往往成为整个MapReduce作业的性能瓶颈,优化Shuffle过程可以显著提升作业的整体执行效率。
3、Shuffle调优策略
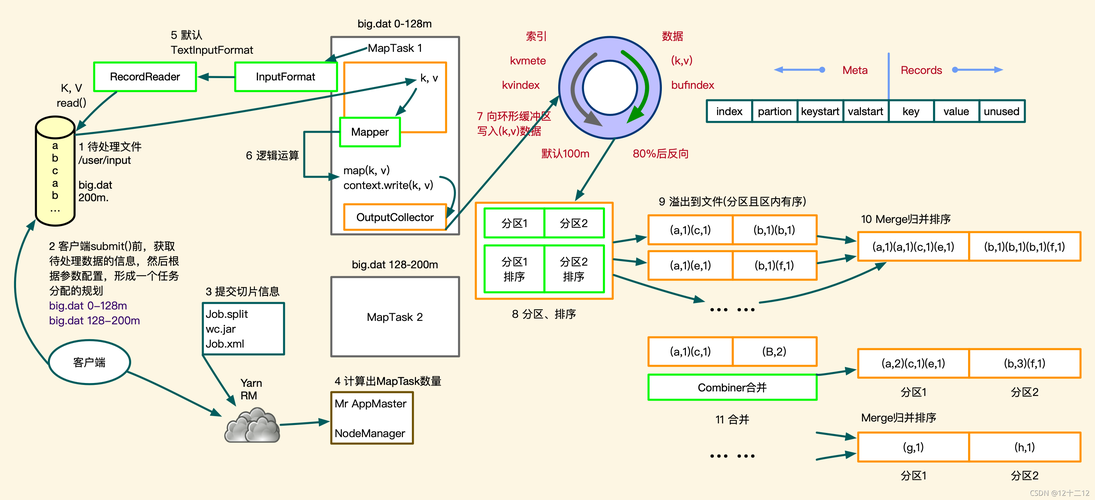
内存配置:合理配置JVM的heapsize至关重要,通过调整mapreduce.reduce.shuffle.input.buffer.percent参数(默认为70%)来控制用于存储Map输出的内存比例,增大这个比例可以为Shuffle过程分配更多的内存,减少磁盘IO操作。
阈值设置:当复制的数据达到一定大小或文件数达到阈值时,内存中的数据将被合并后写入磁盘,这两个阈值分别由mapreduce.reduce.shuffle.merge.percent和mapreduce.reduce.merge.inmem.threshold参数控制,适当调整这些阈值可以减少磁盘写入操作,从而提升性能。
压缩技术:使用压缩技术可以减少网络传输中的数据量,缩短数据传输时间,进而优化Shuffle过程,虽然压缩和解压缩也会消耗一定的CPU资源,但通常这可以由减少的网络传输时间弥补。
4、Shuffle调优实战建议
适应硬件配置:根据实际的硬件配置(如CPU核心数、内存大小等)调整Shuffle相关的参数,在内存较大的环境中,可以适当增加缓冲区的内存分配比率。
监控调优效果:实施任何调优措施后,都需要监控其效果,比如通过比较调优前后的作业运行时间和资源消耗情况,以确认优化的效果。
5、考虑数据特性
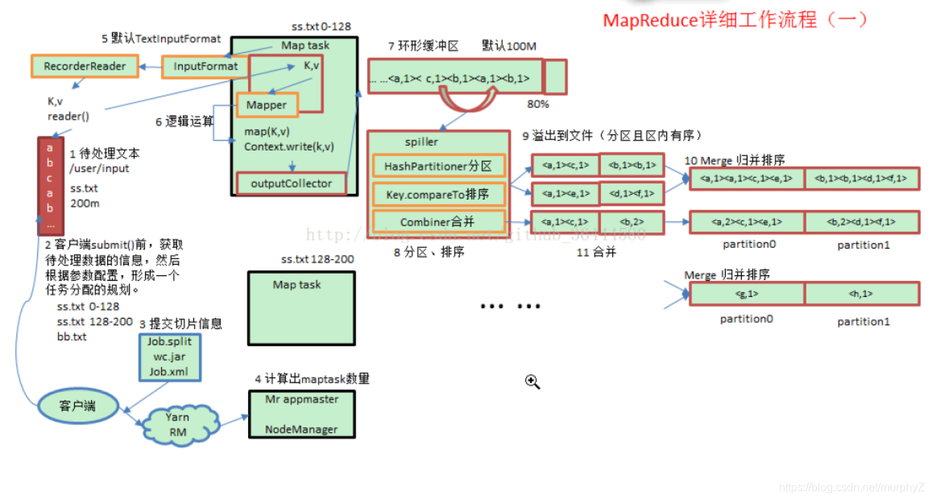
数据倾斜问题:在面对数据倾斜问题时,可以通过调整Partition策略或者启用Map端的combine功能来减少数据处理的倾斜程度,从而优化Shuffle过程。
MapReduce的Shuffle调优是一个涉及多方面因素考量的技术活,通过合理的内存配置、阈值设置、使用压缩技术以及针对具体应用场景的特殊设置,可以有效提升MapReduce作业的执行效率,持续的监控和分析是确保调优效果的关键,接下来将通过一些常见问题进一步巩固对Shuffle调优的理解:
FAQs
Q1: Shuffle调优是否总是需要增大内存配置?
不是,虽然增大内存配置可以提供更多的缓冲空间,减少磁盘IO,但过大的内存配置可能会影响Map和Reduce任务处理业务逻辑时的内存需求,需要根据实际的作业需求和硬件条件进行调整。
Q2: 如何确定Shuffle调优的效果?
可以通过比较调优前后的作业运行时间、资源使用情况(如CPU使用率、磁盘IO等)来评估调优的效果,也可以考虑使用一些专门的性能测试工具进行详细的分析评估。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/891787.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复